House Prices - Advanced Regression Techniques (R)#
Predict sales prices and practice feature engineering, RFs, and gradient boosting
Author: Lingsong Zeng
Date: 04/20/2020
Introduction#
Overview#
This competition runs indefinitely with a rolling leaderboard. Learn more
Description#

Ask a home buyer to describe their dream house, and they probably won’t begin with the height of the basement ceiling or the proximity to an east-west railroad. But this playground competition’s dataset proves that much more influences price negotiations than the number of bedrooms or a white-picket fence.
With 79 explanatory variables describing (almost) every aspect of residential homes in Ames, Iowa, this competition challenges you to predict the final price of each home.
Practice Skills#
Creative feature engineering
Advanced regression techniques like random forest and gradient boosting
Acknowledgments#
The Ames Housing dataset was compiled by Dean De Cock for use in data science education. It’s an incredible alternative for data scientists looking for a modernized and expanded version of the often cited Boston Housing dataset.
Photo by Tom Thain on Unsplash.
Evaluation#
Goal#
It is my job to predict the sales price for each house. For each Id in the test set, predict the value of the SalePrice variable.
Metric#
Submissions are evaluated on Root-Mean-Squared-Error (RMSE) between the logarithm of the predicted value and the logarithm of the observed sales price. (Taking logs means that errors in predicting expensive houses and cheap houses will affect the result equally.)
# Load required packages
suppressWarnings({
library(readr) # Read CSV files
library(dplyr) # Data manipulation
library(tidyr) # Data tidying
library(ggplot2) # Data visualization
library(moments) # Skewness & kurtosis analysis
library(scales) # Scaling and formatting plots
library(VIM) # kNN imputation for missing values
library(car) # Variance Inflation Factor (VIF) for multicollinearity
library(caret) # Machine learning framework (model training & tuning)
library(e1071) # Support Vector Machines (SVM)
library(kernlab) # Advanced SVM implementation
library(glmnet) # Lasso, Ridge, and ElasticNet regression
library(rpart) # Decision Tree modeling
library(rpart.plot) # Decision Tree visualization
library(randomForest) # Random Forest (bagging)
library(xgboost) # Extreme Gradient Boosting (XGBoost)
})
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Attaching package: 'scales'
The following object is masked from 'package:readr':
col_factor
Loading required package: colorspace
Loading required package: grid
VIM is ready to use.
Suggestions and bug-reports can be submitted at: https://github.com/statistikat/VIM/issues
Attaching package: 'VIM'
The following object is masked from 'package:datasets':
sleep
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:dplyr':
recode
Loading required package: lattice
Attaching package: 'e1071'
The following objects are masked from 'package:moments':
kurtosis, moment, skewness
Attaching package: 'kernlab'
The following object is masked from 'package:scales':
alpha
The following object is masked from 'package:ggplot2':
alpha
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Loaded glmnet 4.1-8
randomForest 4.7-1.2
Type rfNews() to see new features/changes/bug fixes.
Attaching package: 'randomForest'
The following object is masked from 'package:ggplot2':
margin
The following object is masked from 'package:dplyr':
combine
Attaching package: 'xgboost'
The following object is masked from 'package:dplyr':
slice
Data#
File descriptions#
train.csv- the training settest.csv- the test setdata_description.txt- full description of each column, originally prepared by Dean De Cock but lightly edited to match the column names used heresample_submission.csv- a benchmark submission from a linear regression on year and month of sale, lot square footage, and number of bedrooms
# Construct file paths
train_path <- file.path("data", "house-prices", "raw", "train.csv")
test_path <- file.path("data", "house-prices", "raw", "test.csv")
# Read data
train <- read_csv(train_path)
test <- read_csv(test_path)
# Extract the Id column
Id <- test$Id
# Remove the Id column
train <- train %>% select(-Id)
test <- test %>% select(-Id)
Rows: 1460 Columns: 81
── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────
Delimiter: ","
chr (43): MSZoning, Street, Alley, LotShape, LandContour, Utilities, LotConf...
dbl (38): Id, MSSubClass, LotFrontage, LotArea, OverallQual, OverallCond, Ye...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 1459 Columns: 80
── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────
Delimiter: ","
chr (43): MSZoning, Street, Alley, LotShape, LandContour, Utilities, LotConf...
dbl (37): Id, MSSubClass, LotFrontage, LotArea, OverallQual, OverallCond, Ye...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Here we using file.path , the dynamic path generation, instead of using hard-coded paths is aiming to provide better compatibility across different platforms.
Different operating systems use different path separators (e.g. Windows uses \, while Linux and macOS use /). file.path automatically chooses the correct separator based on the operating system.
The size of the training dataset and the test dataset are roughly the same. The test dataset has one less column than the training dataset, which is our target column SalePrice.
glimpse(train)
Rows: 1,460
Columns: 80
$ MSSubClass <dbl> 60, 20, 60, 70, 60, 50, 20, 60, 50, 190, 20, 60, 20, 20,…
$ MSZoning <chr> "RL", "RL", "RL", "RL", "RL", "RL", "RL", "RL", "RM", "R…
$ LotFrontage <dbl> 65, 80, 68, 60, 84, 85, 75, NA, 51, 50, 70, 85, NA, 91, …
$ LotArea <dbl> 8450, 9600, 11250, 9550, 14260, 14115, 10084, 10382, 612…
$ Street <chr> "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", "Pave", …
$ Alley <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ LotShape <chr> "Reg", "Reg", "IR1", "IR1", "IR1", "IR1", "Reg", "IR1", …
$ LandContour <chr> "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", "Lvl", …
$ Utilities <chr> "AllPub", "AllPub", "AllPub", "AllPub", "AllPub", "AllPu…
$ LotConfig <chr> "Inside", "FR2", "Inside", "Corner", "FR2", "Inside", "I…
$ LandSlope <chr> "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", "Gtl", …
$ Neighborhood <chr> "CollgCr", "Veenker", "CollgCr", "Crawfor", "NoRidge", "…
$ Condition1 <chr> "Norm", "Feedr", "Norm", "Norm", "Norm", "Norm", "Norm",…
$ Condition2 <chr> "Norm", "Norm", "Norm", "Norm", "Norm", "Norm", "Norm", …
$ BldgType <chr> "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", "1Fam", …
$ HouseStyle <chr> "2Story", "1Story", "2Story", "2Story", "2Story", "1.5Fi…
$ OverallQual <dbl> 7, 6, 7, 7, 8, 5, 8, 7, 7, 5, 5, 9, 5, 7, 6, 7, 6, 4, 5,…
$ OverallCond <dbl> 5, 8, 5, 5, 5, 5, 5, 6, 5, 6, 5, 5, 6, 5, 5, 8, 7, 5, 5,…
$ YearBuilt <dbl> 2003, 1976, 2001, 1915, 2000, 1993, 2004, 1973, 1931, 19…
$ YearRemodAdd <dbl> 2003, 1976, 2002, 1970, 2000, 1995, 2005, 1973, 1950, 19…
$ RoofStyle <chr> "Gable", "Gable", "Gable", "Gable", "Gable", "Gable", "G…
$ RoofMatl <chr> "CompShg", "CompShg", "CompShg", "CompShg", "CompShg", "…
$ Exterior1st <chr> "VinylSd", "MetalSd", "VinylSd", "Wd Sdng", "VinylSd", "…
$ Exterior2nd <chr> "VinylSd", "MetalSd", "VinylSd", "Wd Shng", "VinylSd", "…
$ MasVnrType <chr> "BrkFace", "None", "BrkFace", "None", "BrkFace", "None",…
$ MasVnrArea <dbl> 196, 0, 162, 0, 350, 0, 186, 240, 0, 0, 0, 286, 0, 306, …
$ ExterQual <chr> "Gd", "TA", "Gd", "TA", "Gd", "TA", "Gd", "TA", "TA", "T…
$ ExterCond <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "T…
$ Foundation <chr> "PConc", "CBlock", "PConc", "BrkTil", "PConc", "Wood", "…
$ BsmtQual <chr> "Gd", "Gd", "Gd", "TA", "Gd", "Gd", "Ex", "Gd", "TA", "T…
$ BsmtCond <chr> "TA", "TA", "TA", "Gd", "TA", "TA", "TA", "TA", "TA", "T…
$ BsmtExposure <chr> "No", "Gd", "Mn", "No", "Av", "No", "Av", "Mn", "No", "N…
$ BsmtFinType1 <chr> "GLQ", "ALQ", "GLQ", "ALQ", "GLQ", "GLQ", "GLQ", "ALQ", …
$ BsmtFinSF1 <dbl> 706, 978, 486, 216, 655, 732, 1369, 859, 0, 851, 906, 99…
$ BsmtFinType2 <chr> "Unf", "Unf", "Unf", "Unf", "Unf", "Unf", "Unf", "BLQ", …
$ BsmtFinSF2 <dbl> 0, 0, 0, 0, 0, 0, 0, 32, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ BsmtUnfSF <dbl> 150, 284, 434, 540, 490, 64, 317, 216, 952, 140, 134, 17…
$ TotalBsmtSF <dbl> 856, 1262, 920, 756, 1145, 796, 1686, 1107, 952, 991, 10…
$ Heating <chr> "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", "GasA", …
$ HeatingQC <chr> "Ex", "Ex", "Ex", "Gd", "Ex", "Ex", "Ex", "Ex", "Gd", "E…
$ CentralAir <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "…
$ Electrical <chr> "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr", "SBrkr", "S…
$ `1stFlrSF` <dbl> 856, 1262, 920, 961, 1145, 796, 1694, 1107, 1022, 1077, …
$ `2ndFlrSF` <dbl> 854, 0, 866, 756, 1053, 566, 0, 983, 752, 0, 0, 1142, 0,…
$ LowQualFinSF <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ GrLivArea <dbl> 1710, 1262, 1786, 1717, 2198, 1362, 1694, 2090, 1774, 10…
$ BsmtFullBath <dbl> 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1,…
$ BsmtHalfBath <dbl> 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ FullBath <dbl> 2, 2, 2, 1, 2, 1, 2, 2, 2, 1, 1, 3, 1, 2, 1, 1, 1, 2, 1,…
$ HalfBath <dbl> 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1,…
$ BedroomAbvGr <dbl> 3, 3, 3, 3, 4, 1, 3, 3, 2, 2, 3, 4, 2, 3, 2, 2, 2, 2, 3,…
$ KitchenAbvGr <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1,…
$ KitchenQual <chr> "Gd", "TA", "Gd", "Gd", "Gd", "TA", "Gd", "TA", "TA", "T…
$ TotRmsAbvGrd <dbl> 8, 6, 6, 7, 9, 5, 7, 7, 8, 5, 5, 11, 4, 7, 5, 5, 5, 6, 6…
$ Functional <chr> "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", "Typ", …
$ Fireplaces <dbl> 0, 1, 1, 1, 1, 0, 1, 2, 2, 2, 0, 2, 0, 1, 1, 0, 1, 0, 0,…
$ FireplaceQu <chr> NA, "TA", "TA", "Gd", "TA", NA, "Gd", "TA", "TA", "TA", …
$ GarageType <chr> "Attchd", "Attchd", "Attchd", "Detchd", "Attchd", "Attch…
$ GarageYrBlt <dbl> 2003, 1976, 2001, 1998, 2000, 1993, 2004, 1973, 1931, 19…
$ GarageFinish <chr> "RFn", "RFn", "RFn", "Unf", "RFn", "Unf", "RFn", "RFn", …
$ GarageCars <dbl> 2, 2, 2, 3, 3, 2, 2, 2, 2, 1, 1, 3, 1, 3, 1, 2, 2, 2, 2,…
$ GarageArea <dbl> 548, 460, 608, 642, 836, 480, 636, 484, 468, 205, 384, 7…
$ GarageQual <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "Fa", "G…
$ GarageCond <chr> "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "TA", "T…
$ PavedDrive <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "…
$ WoodDeckSF <dbl> 0, 298, 0, 0, 192, 40, 255, 235, 90, 0, 0, 147, 140, 160…
$ OpenPorchSF <dbl> 61, 0, 42, 35, 84, 30, 57, 204, 0, 4, 0, 21, 0, 33, 213,…
$ EnclosedPorch <dbl> 0, 0, 0, 272, 0, 0, 0, 228, 205, 0, 0, 0, 0, 0, 176, 0, …
$ `3SsnPorch` <dbl> 0, 0, 0, 0, 0, 320, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ ScreenPorch <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 176, 0, 0, 0, 0, 0, …
$ PoolArea <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ PoolQC <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ Fence <chr> NA, NA, NA, NA, NA, "MnPrv", NA, NA, NA, NA, NA, NA, NA,…
$ MiscFeature <chr> NA, NA, NA, NA, NA, "Shed", NA, "Shed", NA, NA, NA, NA, …
$ MiscVal <dbl> 0, 0, 0, 0, 0, 700, 0, 350, 0, 0, 0, 0, 0, 0, 0, 0, 700,…
$ MoSold <dbl> 2, 5, 9, 2, 12, 10, 8, 11, 4, 1, 2, 7, 9, 8, 5, 7, 3, 10…
$ YrSold <dbl> 2008, 2007, 2008, 2006, 2008, 2009, 2007, 2009, 2008, 20…
$ SaleType <chr> "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD", "WD", "W…
$ SaleCondition <chr> "Normal", "Normal", "Normal", "Abnorml", "Normal", "Norm…
$ SalePrice <dbl> 208500, 181500, 223500, 140000, 250000, 143000, 307000, …
Because we will use all features for modeling later, we need to convert all features in chr format to factor format. Therefore, we now need to filter out categorical features and numerical features separately.
categorical_features <- c(
'MSSubClass', 'MSZoning', 'Street', 'Alley', 'LotShape', 'LandContour',
'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1',
'Condition2', 'BldgType', 'HouseStyle', 'RoofStyle', 'RoofMatl',
'Exterior1st', 'Exterior2nd', 'MasVnrType', 'ExterQual', 'ExterCond',
'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1',
'BsmtFinType2', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical',
'KitchenQual', 'Functional', 'FireplaceQu', 'GarageType', 'GarageFinish',
'GarageQual', 'GarageCond', 'PavedDrive', 'PoolQC', 'Fence', 'MiscFeature',
'SaleType', 'SaleCondition', 'OverallQual', 'OverallCond'
)
numerical_features <- c(
'LotFrontage', 'LotArea', 'YearBuilt', 'YearRemodAdd', 'MasVnrArea',
'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', '1stFlrSF',
'2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath',
'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd',
'Fireplaces', 'GarageYrBlt', 'GarageCars', 'GarageArea', 'WoodDeckSF',
'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea',
'MiscVal', 'MoSold', 'YrSold'
)
For categorical_features and numerical_features, the reason we cannot directly select features with values of int64 or float64, because some features such as MSSubClass:
MSSubClass: Identifies the type of dwelling involved in the sale.
20 1-STORY 1946 & NEWER ALL STYLES
30 1-STORY 1945 & OLDER
40 1-STORY W/FINISHED ATTIC ALL AGES
45 1-1/2 STORY - UNFINISHED ALL AGES
50 1-1/2 STORY FINISHED ALL AGES
60 2-STORY 1946 & NEWER
70 2-STORY 1945 & OLDER
75 2-1/2 STORY ALL AGES
80 SPLIT OR MULTI-LEVEL
85 SPLIT FOYER
90 DUPLEX - ALL STYLES AND AGES
120 1-STORY PUD (Planned Unit Development) - 1946 & NEWER
150 1-1/2 STORY PUD - ALL AGES
160 2-STORY PUD - 1946 & NEWER
180 PUD - MULTILEVEL - INCL SPLIT LEV/FOYER
190 2 FAMILY CONVERSION - ALL STYLES AND AGES
Its value is int64 format, but it is actually a categorical feature. Therefore, here I manually distinguish all categorical_features and numerical_features according to the description in data_description.txt.
# Convert all categorical features to factor
train <- train %>%
mutate(across(all_of(categorical_features), as.factor))
test <- test %>%
mutate(across(all_of(categorical_features), as.factor))
glimpse(train)
Rows: 1,460
Columns: 80
$ MSSubClass <fct> 60, 20, 60, 70, 60, 50, 20, 60, 50, 190, 20, 60, 20, 20,…
$ MSZoning <fct> RL, RL, RL, RL, RL, RL, RL, RL, RM, RL, RL, RL, RL, RL, …
$ LotFrontage <dbl> 65, 80, 68, 60, 84, 85, 75, NA, 51, 50, 70, 85, NA, 91, …
$ LotArea <dbl> 8450, 9600, 11250, 9550, 14260, 14115, 10084, 10382, 612…
$ Street <fct> Pave, Pave, Pave, Pave, Pave, Pave, Pave, Pave, Pave, Pa…
$ Alley <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ LotShape <fct> Reg, Reg, IR1, IR1, IR1, IR1, Reg, IR1, Reg, Reg, Reg, I…
$ LandContour <fct> Lvl, Lvl, Lvl, Lvl, Lvl, Lvl, Lvl, Lvl, Lvl, Lvl, Lvl, L…
$ Utilities <fct> AllPub, AllPub, AllPub, AllPub, AllPub, AllPub, AllPub, …
$ LotConfig <fct> Inside, FR2, Inside, Corner, FR2, Inside, Inside, Corner…
$ LandSlope <fct> Gtl, Gtl, Gtl, Gtl, Gtl, Gtl, Gtl, Gtl, Gtl, Gtl, Gtl, G…
$ Neighborhood <fct> CollgCr, Veenker, CollgCr, Crawfor, NoRidge, Mitchel, So…
$ Condition1 <fct> Norm, Feedr, Norm, Norm, Norm, Norm, Norm, PosN, Artery,…
$ Condition2 <fct> Norm, Norm, Norm, Norm, Norm, Norm, Norm, Norm, Norm, Ar…
$ BldgType <fct> 1Fam, 1Fam, 1Fam, 1Fam, 1Fam, 1Fam, 1Fam, 1Fam, 1Fam, 2f…
$ HouseStyle <fct> 2Story, 1Story, 2Story, 2Story, 2Story, 1.5Fin, 1Story, …
$ OverallQual <fct> 7, 6, 7, 7, 8, 5, 8, 7, 7, 5, 5, 9, 5, 7, 6, 7, 6, 4, 5,…
$ OverallCond <fct> 5, 8, 5, 5, 5, 5, 5, 6, 5, 6, 5, 5, 6, 5, 5, 8, 7, 5, 5,…
$ YearBuilt <dbl> 2003, 1976, 2001, 1915, 2000, 1993, 2004, 1973, 1931, 19…
$ YearRemodAdd <dbl> 2003, 1976, 2002, 1970, 2000, 1995, 2005, 1973, 1950, 19…
$ RoofStyle <fct> Gable, Gable, Gable, Gable, Gable, Gable, Gable, Gable, …
$ RoofMatl <fct> CompShg, CompShg, CompShg, CompShg, CompShg, CompShg, Co…
$ Exterior1st <fct> VinylSd, MetalSd, VinylSd, Wd Sdng, VinylSd, VinylSd, Vi…
$ Exterior2nd <fct> VinylSd, MetalSd, VinylSd, Wd Shng, VinylSd, VinylSd, Vi…
$ MasVnrType <fct> BrkFace, None, BrkFace, None, BrkFace, None, Stone, Ston…
$ MasVnrArea <dbl> 196, 0, 162, 0, 350, 0, 186, 240, 0, 0, 0, 286, 0, 306, …
$ ExterQual <fct> Gd, TA, Gd, TA, Gd, TA, Gd, TA, TA, TA, TA, Ex, TA, Gd, …
$ ExterCond <fct> TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, …
$ Foundation <fct> PConc, CBlock, PConc, BrkTil, PConc, Wood, PConc, CBlock…
$ BsmtQual <fct> Gd, Gd, Gd, TA, Gd, Gd, Ex, Gd, TA, TA, TA, Ex, TA, Gd, …
$ BsmtCond <fct> TA, TA, TA, Gd, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, …
$ BsmtExposure <fct> No, Gd, Mn, No, Av, No, Av, Mn, No, No, No, No, No, Av, …
$ BsmtFinType1 <fct> GLQ, ALQ, GLQ, ALQ, GLQ, GLQ, GLQ, ALQ, Unf, GLQ, Rec, G…
$ BsmtFinSF1 <dbl> 706, 978, 486, 216, 655, 732, 1369, 859, 0, 851, 906, 99…
$ BsmtFinType2 <fct> Unf, Unf, Unf, Unf, Unf, Unf, Unf, BLQ, Unf, Unf, Unf, U…
$ BsmtFinSF2 <dbl> 0, 0, 0, 0, 0, 0, 0, 32, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ BsmtUnfSF <dbl> 150, 284, 434, 540, 490, 64, 317, 216, 952, 140, 134, 17…
$ TotalBsmtSF <dbl> 856, 1262, 920, 756, 1145, 796, 1686, 1107, 952, 991, 10…
$ Heating <fct> GasA, GasA, GasA, GasA, GasA, GasA, GasA, GasA, GasA, Ga…
$ HeatingQC <fct> Ex, Ex, Ex, Gd, Ex, Ex, Ex, Ex, Gd, Ex, Ex, Ex, TA, Ex, …
$ CentralAir <fct> Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y,…
$ Electrical <fct> SBrkr, SBrkr, SBrkr, SBrkr, SBrkr, SBrkr, SBrkr, SBrkr, …
$ `1stFlrSF` <dbl> 856, 1262, 920, 961, 1145, 796, 1694, 1107, 1022, 1077, …
$ `2ndFlrSF` <dbl> 854, 0, 866, 756, 1053, 566, 0, 983, 752, 0, 0, 1142, 0,…
$ LowQualFinSF <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ GrLivArea <dbl> 1710, 1262, 1786, 1717, 2198, 1362, 1694, 2090, 1774, 10…
$ BsmtFullBath <dbl> 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1,…
$ BsmtHalfBath <dbl> 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ FullBath <dbl> 2, 2, 2, 1, 2, 1, 2, 2, 2, 1, 1, 3, 1, 2, 1, 1, 1, 2, 1,…
$ HalfBath <dbl> 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1,…
$ BedroomAbvGr <dbl> 3, 3, 3, 3, 4, 1, 3, 3, 2, 2, 3, 4, 2, 3, 2, 2, 2, 2, 3,…
$ KitchenAbvGr <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1,…
$ KitchenQual <fct> Gd, TA, Gd, Gd, Gd, TA, Gd, TA, TA, TA, TA, Ex, TA, Gd, …
$ TotRmsAbvGrd <dbl> 8, 6, 6, 7, 9, 5, 7, 7, 8, 5, 5, 11, 4, 7, 5, 5, 5, 6, 6…
$ Functional <fct> Typ, Typ, Typ, Typ, Typ, Typ, Typ, Typ, Min1, Typ, Typ, …
$ Fireplaces <dbl> 0, 1, 1, 1, 1, 0, 1, 2, 2, 2, 0, 2, 0, 1, 1, 0, 1, 0, 0,…
$ FireplaceQu <fct> NA, TA, TA, Gd, TA, NA, Gd, TA, TA, TA, NA, Gd, NA, Gd, …
$ GarageType <fct> Attchd, Attchd, Attchd, Detchd, Attchd, Attchd, Attchd, …
$ GarageYrBlt <dbl> 2003, 1976, 2001, 1998, 2000, 1993, 2004, 1973, 1931, 19…
$ GarageFinish <fct> RFn, RFn, RFn, Unf, RFn, Unf, RFn, RFn, Unf, RFn, Unf, F…
$ GarageCars <dbl> 2, 2, 2, 3, 3, 2, 2, 2, 2, 1, 1, 3, 1, 3, 1, 2, 2, 2, 2,…
$ GarageArea <dbl> 548, 460, 608, 642, 836, 480, 636, 484, 468, 205, 384, 7…
$ GarageQual <fct> TA, TA, TA, TA, TA, TA, TA, TA, Fa, Gd, TA, TA, TA, TA, …
$ GarageCond <fct> TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, TA, …
$ PavedDrive <fct> Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y, Y,…
$ WoodDeckSF <dbl> 0, 298, 0, 0, 192, 40, 255, 235, 90, 0, 0, 147, 140, 160…
$ OpenPorchSF <dbl> 61, 0, 42, 35, 84, 30, 57, 204, 0, 4, 0, 21, 0, 33, 213,…
$ EnclosedPorch <dbl> 0, 0, 0, 272, 0, 0, 0, 228, 205, 0, 0, 0, 0, 0, 176, 0, …
$ `3SsnPorch` <dbl> 0, 0, 0, 0, 0, 320, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ ScreenPorch <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 176, 0, 0, 0, 0, 0, …
$ PoolArea <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ PoolQC <fct> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ Fence <fct> NA, NA, NA, NA, NA, MnPrv, NA, NA, NA, NA, NA, NA, NA, N…
$ MiscFeature <fct> NA, NA, NA, NA, NA, Shed, NA, Shed, NA, NA, NA, NA, NA, …
$ MiscVal <dbl> 0, 0, 0, 0, 0, 700, 0, 350, 0, 0, 0, 0, 0, 0, 0, 0, 700,…
$ MoSold <dbl> 2, 5, 9, 2, 12, 10, 8, 11, 4, 1, 2, 7, 9, 8, 5, 7, 3, 10…
$ YrSold <dbl> 2008, 2007, 2008, 2006, 2008, 2009, 2007, 2009, 2008, 20…
$ SaleType <fct> WD, WD, WD, WD, WD, WD, WD, WD, WD, WD, WD, New, WD, New…
$ SaleCondition <fct> Normal, Normal, Normal, Abnorml, Normal, Normal, Normal,…
$ SalePrice <dbl> 208500, 181500, 223500, 140000, 250000, 143000, 307000, …
# Define the variables where NA means "None"
none_features <- c(
"Alley", "BsmtQual", "BsmtCond", "BsmtExposure",
"BsmtFinType1", "BsmtFinType2", "FireplaceQu", "GarageType",
"GarageFinish", "GarageQual", "GarageCond", "PoolQC",
"Fence", "MiscFeature"
)
According to the description in data_description.txt, NA in some features does not mean Missing Value, but means that the observation does not have the feature, such as Alley:
Alley: Type of alley access to property
Grvl Gravel
Pave Paved
NA No alley access
Therefore, the missing value filling treatment of these features should be different. I filtered out all similar features here to prepare for the missing value filling in the subsequent preprocessing.
# Replace NA with "None" and ensure "None" is the lowest factor level
train <- train %>%
mutate(
across(all_of(none_features),
~ factor(
replace_na(as.character(.), "None"), # fill NA by "None"
levels = c("None", sort(unique(as.character(na.omit(.))))) # redefine factor levels
)
)
)
test <- test %>%
mutate(
across(
all_of(none_features),
~ factor(
replace_na(as.character(.), "None"),
levels = c("None", sort(unique(as.character(na.omit(.)))))
)
)
)
# Verify the changes
summary(train[none_features])
Alley BsmtQual BsmtCond BsmtExposure BsmtFinType1 BsmtFinType2
None:1369 None: 37 None: 37 None: 38 None: 37 None: 38
Grvl: 50 Ex :121 Fa : 45 Av :221 ALQ :220 ALQ : 19
Pave: 41 Fa : 35 Gd : 65 Gd :134 BLQ :148 BLQ : 33
Gd :618 Po : 2 Mn :114 GLQ :418 GLQ : 14
TA :649 TA :1311 No :953 LwQ : 74 LwQ : 46
Rec :133 Rec : 54
Unf :430 Unf :1256
FireplaceQu GarageType GarageFinish GarageQual GarageCond PoolQC
None:690 None : 81 None: 81 None: 81 None: 81 None:1453
Ex : 24 2Types : 6 Fin :352 Ex : 3 Ex : 2 Ex : 2
Fa : 33 Attchd :870 RFn :422 Fa : 48 Fa : 35 Fa : 2
Gd :380 Basment: 19 Unf :605 Gd : 14 Gd : 9 Gd : 3
Po : 20 BuiltIn: 88 Po : 3 Po : 7
TA :313 CarPort: 9 TA :1311 TA :1326
Detchd :387
Fence MiscFeature
None :1179 None:1406
GdPrv: 59 Gar2: 2
GdWo : 54 Othr: 2
MnPrv: 157 Shed: 49
MnWw : 11 TenC: 1
ordinal_features <- c(
"MSSubClass", "OverallQual", "OverallCond", "LotShape", "LandSlope",
"ExterQual", "ExterCond", "BsmtQual", "BsmtCond", "BsmtExposure",
"BsmtFinType1", "BsmtFinType2", "HeatingQC", "KitchenQual",
"Functional", "FireplaceQu", "GarageFinish", "GarageQual", "GarageCond",
"PavedDrive", "PoolQC", "Fence"
)
nominal_features <- c(
"MSZoning", "Street", "Alley", "LandContour", "Utilities", "LotConfig",
"Neighborhood", "Condition1", "Condition2", "BldgType", "HouseStyle",
"RoofStyle", "RoofMatl", "Exterior1st", "Exterior2nd", "MasVnrType",
"Foundation", "Heating", "CentralAir", "Electrical", "GarageType",
"MiscFeature", "SaleType", "SaleCondition"
)
Similarly, I also distinguish between ordinal_features and nominal_features here to facilitate subsequent preprocessing. The main difference between them is whether the variable values are ordered. The following are examples of an ordinal feature and a nominal feature respectively.
ExterQual: Evaluates the quality of the material on the exterior
Ex Excellent
Gd Good
TA Average/Typical
Fa Fair
Po Poor
MSZoning: Identifies the general zoning classification of the sale.
A Agriculture
C Commercial
FV Floating Village Residential
I Industrial
RH Residential High Density
RL Residential Low Density
RP Residential Low Density Park
RM Residential Medium Density
In the following preprocessing, ordinal features will be applied with Label Encoding, while nominal features will be applied with One-Hot Encoding.
EDA#
summary(train$SalePrice)
Min. 1st Qu. Median Mean 3rd Qu. Max.
34900 129975 163000 180921 214000 755000
options(repr.plot.width = 10, repr.plot.height = 8)
# Create a tibble with SalePrice
train %>%
ggplot(aes(x = SalePrice)) +
geom_histogram(aes(fill = after_stat(count)), bins = 30, color = "black", alpha = 0.8) +
scale_fill_viridis_c(name = "SalePrice", option = "plasma") +
geom_vline(
aes(xintercept = mean(SalePrice, na.rm = TRUE)),
linetype = "dashed", linewidth = 1.2, color = "red"
) +
scale_x_continuous(labels = comma_format()) + # not use scientific notation
labs(
x = "SalePrice",
y = "Count",
title = "SalePrice Distribution",
caption = "Histogram with Adjusted Density Plot"
) +
theme_minimal(base_size = 14)
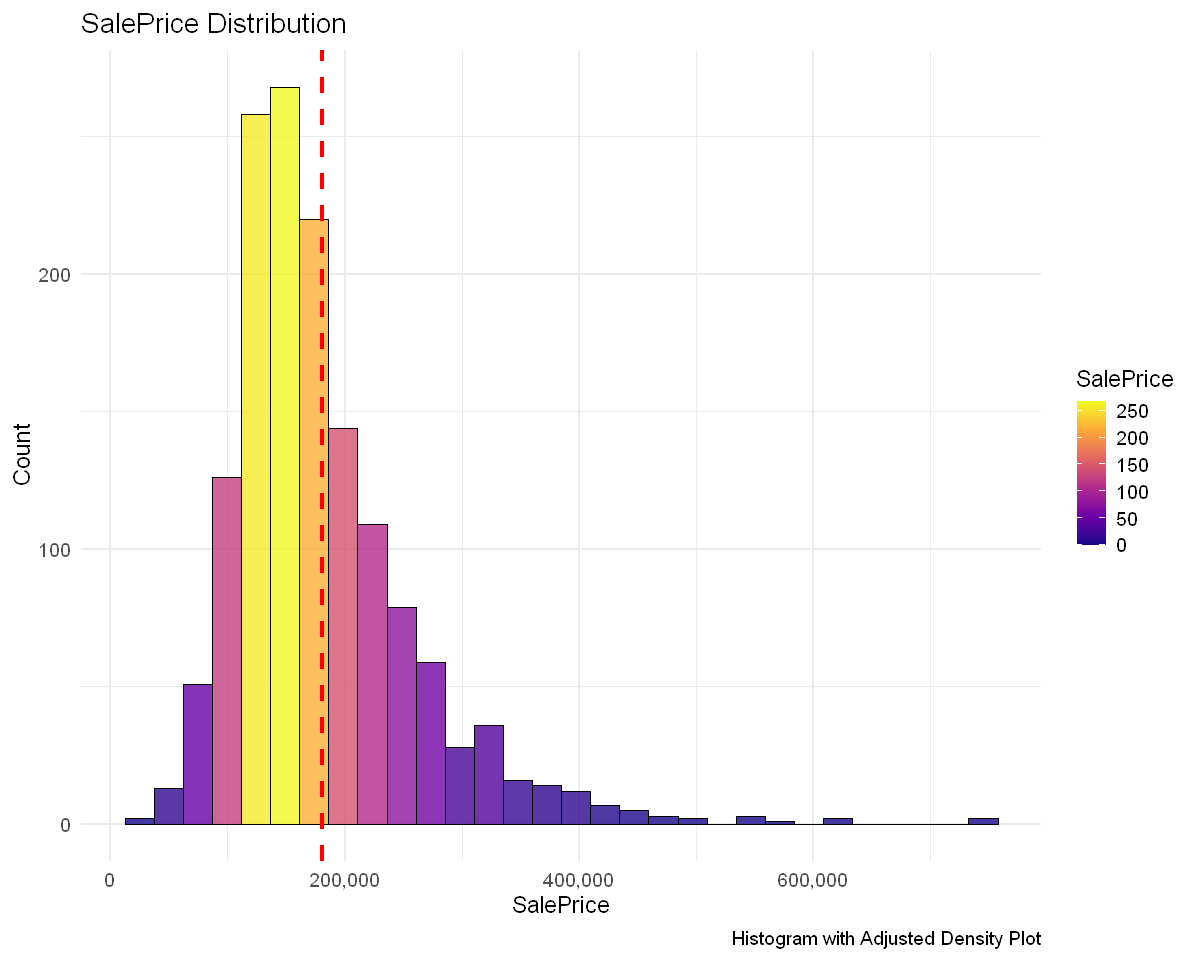
# Calculate skewness and kurtosis
skewness_value <- skewness(train$SalePrice, na.rm = TRUE)
kurtosis_value <- kurtosis(train$SalePrice, na.rm = TRUE)
# Print skewness and kurtosis
cat("Skewness of SalePrice:", skewness_value, "\n")
cat("Kurtosis of SalePrice:", kurtosis_value, "\n")
Skewness of SalePrice: 1.879009
Kurtosis of SalePrice: 6.496789
From the histogram and the calculated value of skewness (1.88), we can see that the distribution of SalePrice is right-skewed. This may have a negative impact on the training of the model. So we need a log transformation for SalePrice.
# Log transformation of SalePrice
train <- train %>%
mutate(SalePrice_log = log(SalePrice))
# Plot the distribution of log-transformed SalePrice
ggplot(train, aes(x = SalePrice_log)) +
geom_histogram(aes(fill = after_stat(count)), bins = 30, color = "black", alpha = 0.8) +
scale_fill_viridis_c(name = "Log SalePrice", option = "plasma") +
geom_vline(
aes(xintercept = mean(SalePrice_log, na.rm = TRUE)),
linetype = "dashed", linewidth = 1.2, color = "red"
) +
scale_x_continuous(labels = comma_format()) + # not use scientific notation
labs(
x = "Log(SalePrice)",
y = "Count",
title = "Log-Transformed SalePrice Distribution",
caption = "Histogram of Log-Transformed SalePrice"
) +
theme_minimal(base_size = 14)
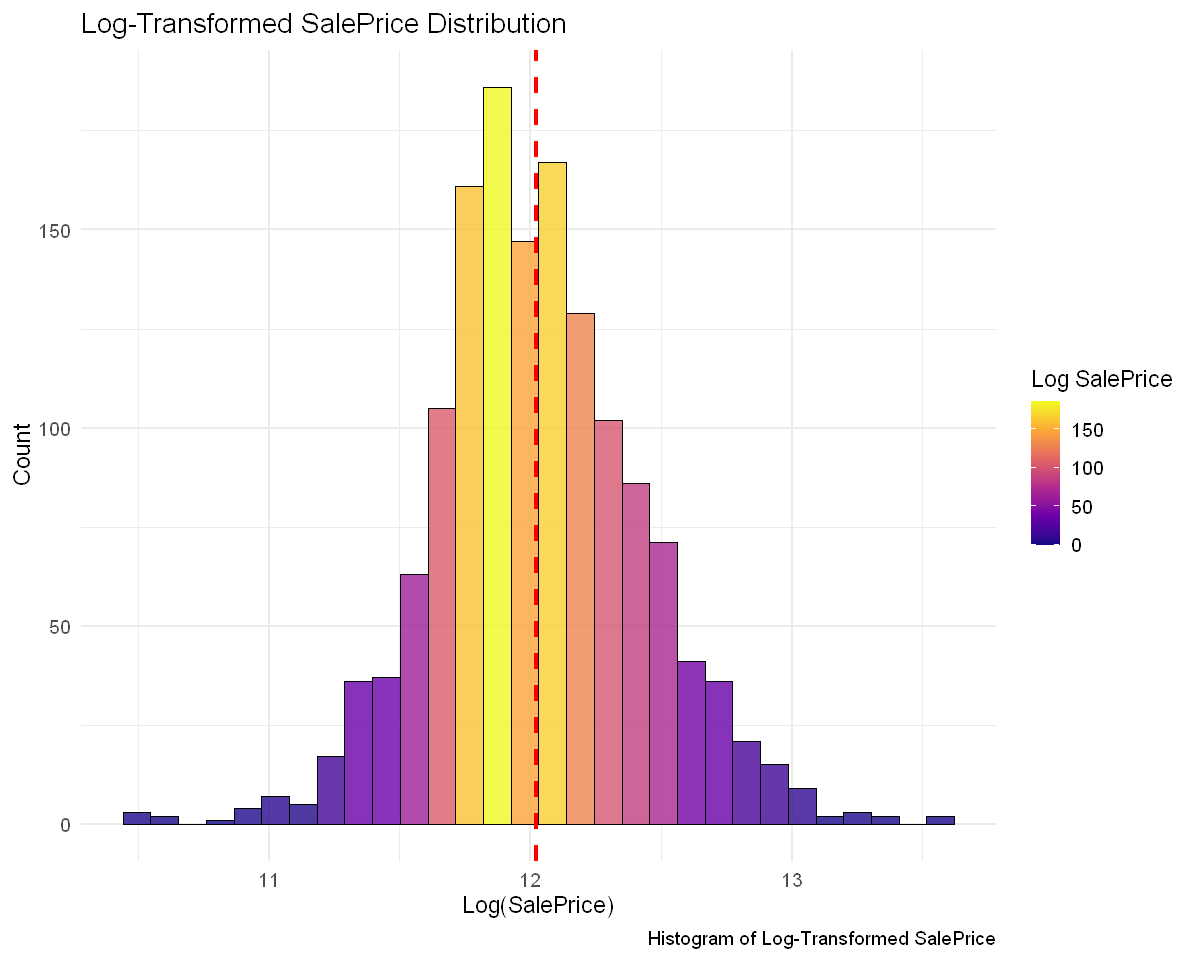
# Calculate skewness and kurtosis for log-transformed SalePrice
skewness_log <- skewness(train$SalePrice_log, na.rm = TRUE)
kurtosis_log <- kurtosis(train$SalePrice_log, na.rm = TRUE)
# Print skewness and kurtosis
cat("Log-Transformed SalePrice_log Skewness:", skewness_log, "\n")
cat("Log-Transformed SalePrice_log Kurtosis:", kurtosis_log, "\n")
Log-Transformed SalePrice_log Skewness: 0.1210859
Log-Transformed SalePrice_log Kurtosis: 0.7974482
From the charts and statistics, we can see that after logarithmic transformation, the distribution of SalePrice is closer to normal distribution.
# Remove the original SalePrice column
train <- train %>% select(-SalePrice)
The following is the distribution of the remaining numerical features:
options(repr.plot.width = 15, repr.plot.height = 15)
# Convert train dataset to long format and remove NA/Inf values
train %>%
select(all_of(numerical_features)) %>%
pivot_longer(cols = everything(), names_to = "Feature", values_to = "Value") %>%
filter(!is.na(Value) & is.finite(Value)) %>% # Remove NA and Inf values
# Plot histograms for all numerical features
ggplot(aes(x = Value)) +
geom_histogram(bins = 10, fill = "blue", color = "black", alpha = 0.7) +
facet_wrap(~ Feature, scales = "free") + # Free scales to adjust for different ranges
labs(title = "Distribution of Numerical Features", x = "Value", y = "Count") +
theme_minimal(base_size = 14)
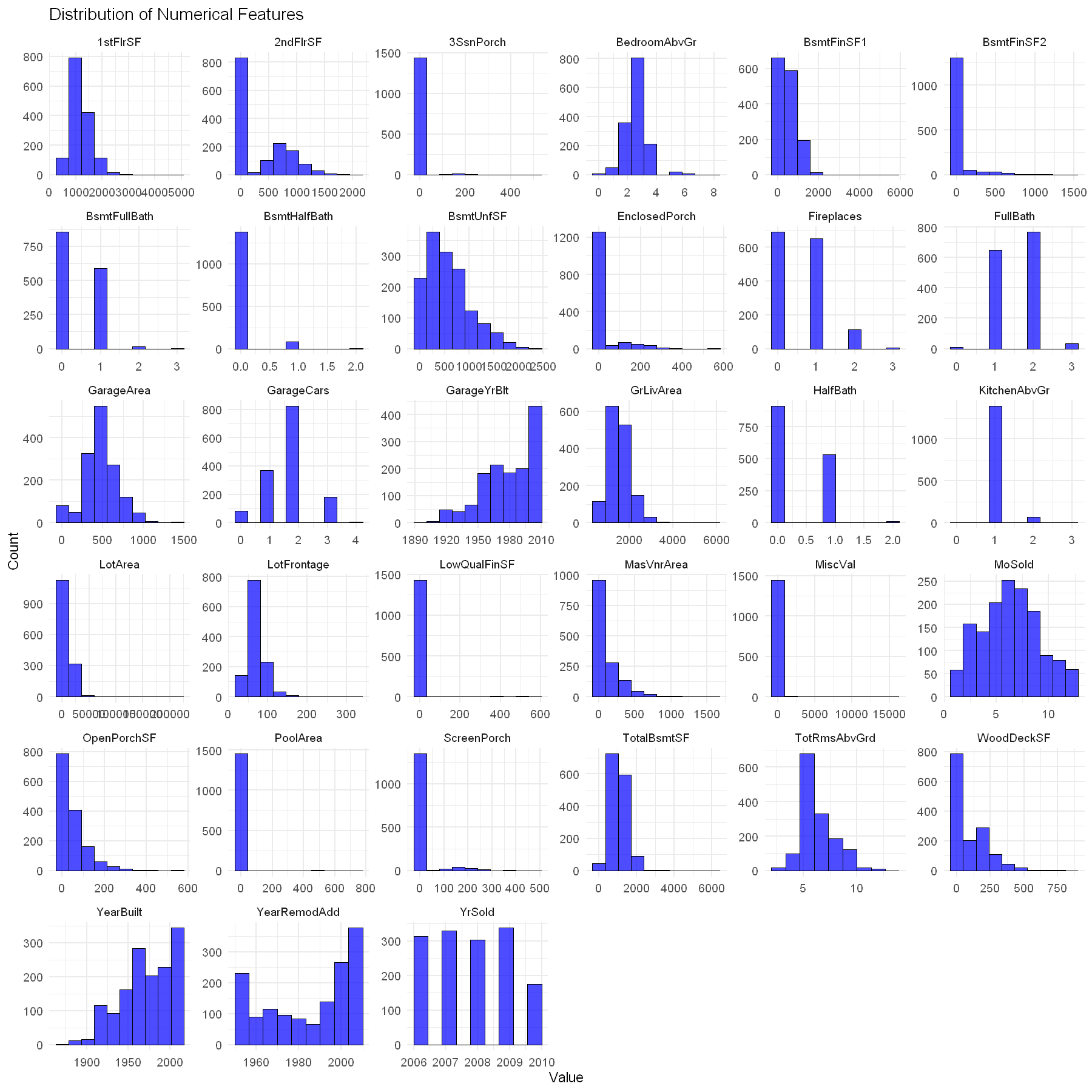
Feature Engineering#
# Function to add features
add_features <- function(data, create_interactions = TRUE, create_base_features = TRUE) {
# Create a new dataframe to store features
new_features <- data.frame(row.names = rownames(data))
# Base features
if (create_base_features) {
new_features$HouseAge <- data$YrSold - data$YearBuilt
new_features$RemodelAge <- data$YrSold - data$YearRemodAdd
new_features$TotalSF <- data$`1stFlrSF` + data$`2ndFlrSF` + data$TotalBsmtSF
}
# Merge new features into the original dataset
data <- cbind(data, new_features)
return(data)
}
# Apply feature engineering to train and test datasets
train <- add_features(train)
test <- add_features(test)
# Define new features
new_features <- c("HouseAge", "RemodelAge", "TotalSF")
# Update numerical_features list
numerical_features <- c(numerical_features, new_features)
options(repr.plot.width = 12, repr.plot.height = 4)
# Plot histograms for new features
train %>%
select(all_of(new_features)) %>%
pivot_longer(cols = everything(), names_to = "Feature", values_to = "Value") %>%
ggplot(aes(x = Value)) +
geom_histogram(bins = 10, fill = "blue", color = "black", alpha = 0.7) +
facet_wrap(~ Feature, scales = "free") +
labs(title = "Distribution of Newly Created Features", x = "Value", y = "Count") +
theme_minimal(base_size = 14)
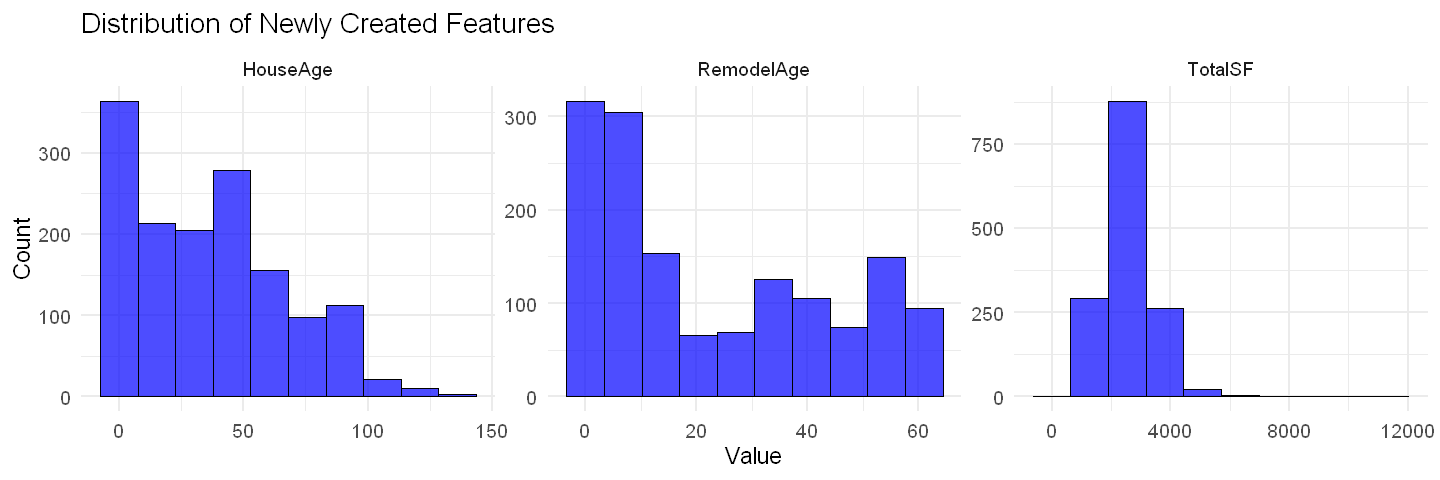
Preprocessing#
Handling Missing Values#
# Function to find columns with NA
check_na <- function(data) {
na_count <- colSums(is.na(data))
na_count <- sort(na_count[na_count > 0], decreasing = TRUE) # Only keep columns with NA
return(as.data.frame(na_count))
}
# Check missing values in train and test
na_train <- check_na(train)
na_test <- check_na(test)
# Print missing value summary
cat("Missing Values in Train Dataset:\n")
print(na_train)
cat("\nMissing Values in Test Dataset:\n")
print(na_test)
Missing Values in Train Dataset:
na_count
LotFrontage 259
GarageYrBlt 81
MasVnrType 8
MasVnrArea 8
Electrical 1
Missing Values in Test Dataset:
na_count
LotFrontage 227
GarageYrBlt 78
MasVnrType 16
MasVnrArea 15
MSZoning 4
Utilities 2
BsmtFullBath 2
BsmtHalfBath 2
Functional 2
Exterior1st 1
Exterior2nd 1
BsmtFinSF1 1
BsmtFinSF2 1
BsmtUnfSF 1
TotalBsmtSF 1
KitchenQual 1
GarageCars 1
GarageArea 1
SaleType 1
TotalSF 1
NA for these variables means the structure does not exist and should be filled with 0:
GarageYrBlt(year garage was built)MasVnrArea(brick facing area)BsmtFinSF1,BsmtFinSF2,BsmtUnfSF(basement area)TotalBsmtSF(total basement area)GarageCars(number of garage spaces)GarageArea(garage area)TotalSF(total area, usually equal to1stFlrSF+2ndFlrSF+TotalBsmtSF)
zero_fill_features <- c("GarageYrBlt", "MasVnrArea", "BsmtFinSF1",
"BsmtFinSF2", "BsmtUnfSF", "TotalBsmtSF",
"GarageCars", "GarageArea", "TotalSF")
train[zero_fill_features] <- lapply(train[zero_fill_features], function(x) replace(x, is.na(x), 0))
test[zero_fill_features] <- lapply(test[zero_fill_features], function(x) replace(x, is.na(x), 0))
NA for these variables may be missing data entries and should be filled with the most common category (Mode):
MasVnrType(brickwork finish type)Electrical(electrical system)MSZoning(land zoning)Utilities(public facilities)Functional(house function)Exterior1st,Exterior2nd(exterior wall material)KitchenQual(kitchen quality)SaleType(sale type)
mode_fill_features <- c("MasVnrType", "Electrical", "MSZoning",
"Utilities", "Functional", "Exterior1st",
"Exterior2nd", "KitchenQual", "SaleType")
fill_mode <- function(x) {
mode_value <- names(sort(table(x), decreasing = TRUE))[1] # get mode
replace(x, is.na(x), mode_value)
}
train[mode_fill_features] <- lapply(train[mode_fill_features], fill_mode)
test[mode_fill_features] <- lapply(test[mode_fill_features], fill_mode)
NA values for these variables may be missing values, and filling the median value can reduce the impact of outliers:
LotFrontage(street frontage length)
train <- train %>%
group_by(Neighborhood) %>%
mutate(LotFrontage = ifelse(is.na(LotFrontage), median(LotFrontage, na.rm = TRUE), LotFrontage)) %>%
ungroup()
test <- test %>%
group_by(Neighborhood) %>%
mutate(LotFrontage = ifelse(is.na(LotFrontage), median(LotFrontage, na.rm = TRUE), LotFrontage)) %>%
ungroup()
Filled with 0 or 1 (integer feature)
BsmtFullBath,BsmtHalfBath(basement bathrooms)
If there is no basement, the number of bathrooms should be 0.
bath_fill_features <- c("BsmtFullBath", "BsmtHalfBath")
train[bath_fill_features] <- lapply(train[bath_fill_features], function(x) replace(x, is.na(x), 0))
test[bath_fill_features] <- lapply(test[bath_fill_features], function(x) replace(x, is.na(x), 0))
Recheck NA
na_train_after <- check_na(train)
na_test_after <- check_na(test)
cat("After processing, missing values in Train Dataset:\n")
print(na_train_after)
cat("\nAfter processing, missing values in Test Dataset:\n")
print(na_test_after)
After processing, missing values in Train Dataset:
[1] na_count
<0 rows> (or 0-length row.names)
After processing, missing values in Test Dataset:
[1] na_count
<0 rows> (or 0-length row.names)
Encoding#
Label Encoding#
Although we previously converted all features that type is chr to fct. However, when you convert a feature to a factor in R, the levels are automatically assigned based on lexicographic (alphabetical/numeric) order, unless specified otherwise. For example, the default order of factor(c("Good", "Bad", "Excellent")) is: Bad → Excellent → Good (alphabetical). If our categorical feature represents a ranking (e.g., Ex > Gd > TA > Fa > Po), incorrect ordering will mislead models that rely on factor levels (e.g., linear regression, decision trees). Therefore, to be on the safe side, we need to perform manual Label Encoding at this time to confirm again that our preprocessing of ordinal_features is correct.
factor_levels <- list(
# Basement Quality (higher is better)
BsmtQual = c("None", "Po", "Fa", "TA", "Gd", "Ex"),
# Basement Condition (higher is better)
BsmtCond = c("None", "Po", "Fa", "TA", "Gd", "Ex"),
# Basement Exposure (higher means more exposure to outside)
BsmtExposure = c("None", "No", "Mn", "Av", "Gd"),
# Basement Finishing Type (higher is more finished)
BsmtFinType1 = c("None", "Unf", "LwQ", "Rec", "BLQ", "ALQ", "GLQ"),
BsmtFinType2 = c("None", "Unf", "LwQ", "Rec", "BLQ", "ALQ", "GLQ"),
# Heating Quality (higher is better)
HeatingQC = c("Po", "Fa", "TA", "Gd", "Ex"),
# Kitchen Quality (higher is better)
KitchenQual = c("Po", "Fa", "TA", "Gd", "Ex"),
# Functional Condition of House
Functional = c("Sal", "Sev", "Maj2", "Maj1", "Mod", "Min2", "Min1", "Typ"),
# Fireplace Quality (higher is better)
FireplaceQu = c("None", "Po", "Fa", "TA", "Gd", "Ex"),
# Garage Finish (higher is more finished)
GarageFinish = c("None", "Unf", "RFn", "Fin"),
# Garage Quality (higher is better)
GarageQual = c("None", "Po", "Fa", "TA", "Gd", "Ex"),
# Garage Condition (higher is better)
GarageCond = c("None", "Po", "Fa", "TA", "Gd", "Ex"),
# Paved Driveway (Y = Paved, P = Partial, N = Dirt/Gravel)
PavedDrive = c("N", "P", "Y"),
# Pool Quality (higher is better)
PoolQC = c("None", "Fa", "TA", "Gd", "Ex"),
# Fence Quality (higher means better privacy/security)
Fence = c("None", "MnWw", "GdWo", "MnPrv", "GdPrv"),
# Sale Condition (Normal is typical)
SaleCondition = c("AdjLand", "Alloca", "Family", "Normal", "Abnorml", "Partial"),
# Lot Shape (Regular is the best)
LotShape = c("IR3", "IR2", "IR1", "Reg"),
# Land Slope (Gtl = gentle slope, best)
LandSlope = c("Sev", "Mod", "Gtl"),
# MSSubClass (Type of dwelling, as a categorical feature)
MSSubClass = c("20", "30", "40", "45", "50", "60", "70", "75", "80", "85",
"90", "120", "150", "160", "180", "190"),
# Overall Quality (numeric but treated as an ordinal feature)
OverallQual = as.character(1:10), # 1 (Worst) to 10 (Best)
# Overall Condition (numeric but treated as an ordinal feature)
OverallCond = as.character(1:10) # 1 (Poor) to 10 (Excellent)
)
for (feature in names(factor_levels)) {
train[[feature]] <- factor(train[[feature]], levels = factor_levels[[feature]])
test[[feature]] <- factor(test[[feature]], levels = factor_levels[[feature]])
}
Tree models such as Random Forest (RF), XGBoost, LightGBM, and CatBoost can directly process raw categorical data, so performance may be reduced due to unnecessary preprocessing.
tree_train <- as.data.frame(train)
tree_test <- as.data.frame(test)
One-Hot Encoding#
# Ensure test dataset has the same factor levels as train
for (col in categorical_features) {
if (col %in% names(test)) {
test[[col]] <- factor(test[[col]], levels = levels(train[[col]]))
}
}
# Apply One-Hot Encoding using predefined categorical_features
ohe <- dummyVars(~ ., data = train[, categorical_features])
# Apply transformation to train and test sets
train_ohe <- predict(ohe, train)
test_ohe <- predict(ohe, test)
# Merge transformed categorical features with numerical features
train <- cbind(train[, numerical_features], train_ohe, SalePrice_log = train$SalePrice_log)
test <- cbind(test[, numerical_features], test_ohe)
# Ensure all variables are numeric
str(train)
'data.frame': 1460 obs. of 344 variables:
$ LotFrontage : num 65 80 68 60 84 85 75 80 51 50 ...
$ LotArea : num 8450 9600 11250 9550 14260 ...
$ YearBuilt : num 2003 1976 2001 1915 2000 ...
$ YearRemodAdd : num 2003 1976 2002 1970 2000 ...
$ MasVnrArea : num 196 0 162 0 350 0 186 240 0 0 ...
$ BsmtFinSF1 : num 706 978 486 216 655 ...
$ BsmtFinSF2 : num 0 0 0 0 0 0 0 32 0 0 ...
$ BsmtUnfSF : num 150 284 434 540 490 64 317 216 952 140 ...
$ TotalBsmtSF : num 856 1262 920 756 1145 ...
$ 1stFlrSF : num 856 1262 920 961 1145 ...
$ 2ndFlrSF : num 854 0 866 756 1053 ...
$ LowQualFinSF : num 0 0 0 0 0 0 0 0 0 0 ...
$ GrLivArea : num 1710 1262 1786 1717 2198 ...
$ BsmtFullBath : num 1 0 1 1 1 1 1 1 0 1 ...
$ BsmtHalfBath : num 0 1 0 0 0 0 0 0 0 0 ...
$ FullBath : num 2 2 2 1 2 1 2 2 2 1 ...
$ HalfBath : num 1 0 1 0 1 1 0 1 0 0 ...
$ BedroomAbvGr : num 3 3 3 3 4 1 3 3 2 2 ...
$ KitchenAbvGr : num 1 1 1 1 1 1 1 1 2 2 ...
$ TotRmsAbvGrd : num 8 6 6 7 9 5 7 7 8 5 ...
$ Fireplaces : num 0 1 1 1 1 0 1 2 2 2 ...
$ GarageYrBlt : num 2003 1976 2001 1998 2000 ...
$ GarageCars : num 2 2 2 3 3 2 2 2 2 1 ...
$ GarageArea : num 548 460 608 642 836 480 636 484 468 205 ...
$ WoodDeckSF : num 0 298 0 0 192 40 255 235 90 0 ...
$ OpenPorchSF : num 61 0 42 35 84 30 57 204 0 4 ...
$ EnclosedPorch : num 0 0 0 272 0 0 0 228 205 0 ...
$ 3SsnPorch : num 0 0 0 0 0 320 0 0 0 0 ...
$ ScreenPorch : num 0 0 0 0 0 0 0 0 0 0 ...
$ PoolArea : num 0 0 0 0 0 0 0 0 0 0 ...
$ MiscVal : num 0 0 0 0 0 700 0 350 0 0 ...
$ MoSold : num 2 5 9 2 12 10 8 11 4 1 ...
$ YrSold : num 2008 2007 2008 2006 2008 ...
$ HouseAge : num 5 31 7 91 8 16 3 36 77 69 ...
$ RemodelAge : num 5 31 6 36 8 14 2 36 58 58 ...
$ TotalSF : num 2566 2524 2706 2473 3343 ...
$ MSSubClass.20 : num 0 1 0 0 0 0 1 0 0 0 ...
$ MSSubClass.30 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.40 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.45 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.50 : num 0 0 0 0 0 1 0 0 1 0 ...
$ MSSubClass.60 : num 1 0 1 0 1 0 0 1 0 0 ...
$ MSSubClass.70 : num 0 0 0 1 0 0 0 0 0 0 ...
$ MSSubClass.75 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.80 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.85 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.90 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.120 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.150 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.160 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.180 : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSSubClass.190 : num 0 0 0 0 0 0 0 0 0 1 ...
$ MSZoning.C (all) : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSZoning.FV : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSZoning.RH : num 0 0 0 0 0 0 0 0 0 0 ...
$ MSZoning.RL : num 1 1 1 1 1 1 1 1 0 1 ...
$ MSZoning.RM : num 0 0 0 0 0 0 0 0 1 0 ...
$ Street.Grvl : num 0 0 0 0 0 0 0 0 0 0 ...
$ Street.Pave : num 1 1 1 1 1 1 1 1 1 1 ...
$ Alley.None : num 1 1 1 1 1 1 1 1 1 1 ...
$ Alley.Grvl : num 0 0 0 0 0 0 0 0 0 0 ...
$ Alley.Pave : num 0 0 0 0 0 0 0 0 0 0 ...
$ LotShape.IR3 : num 0 0 0 0 0 0 0 0 0 0 ...
$ LotShape.IR2 : num 0 0 0 0 0 0 0 0 0 0 ...
$ LotShape.IR1 : num 0 0 1 1 1 1 0 1 0 0 ...
$ LotShape.Reg : num 1 1 0 0 0 0 1 0 1 1 ...
$ LandContour.Bnk : num 0 0 0 0 0 0 0 0 0 0 ...
$ LandContour.HLS : num 0 0 0 0 0 0 0 0 0 0 ...
$ LandContour.Low : num 0 0 0 0 0 0 0 0 0 0 ...
$ LandContour.Lvl : num 1 1 1 1 1 1 1 1 1 1 ...
$ Utilities.AllPub : num 1 1 1 1 1 1 1 1 1 1 ...
$ Utilities.NoSeWa : num 0 0 0 0 0 0 0 0 0 0 ...
$ LotConfig.Corner : num 0 0 0 1 0 0 0 1 0 1 ...
$ LotConfig.CulDSac : num 0 0 0 0 0 0 0 0 0 0 ...
$ LotConfig.FR2 : num 0 1 0 0 1 0 0 0 0 0 ...
$ LotConfig.FR3 : num 0 0 0 0 0 0 0 0 0 0 ...
$ LotConfig.Inside : num 1 0 1 0 0 1 1 0 1 0 ...
$ LandSlope.Sev : num 0 0 0 0 0 0 0 0 0 0 ...
$ LandSlope.Mod : num 0 0 0 0 0 0 0 0 0 0 ...
$ LandSlope.Gtl : num 1 1 1 1 1 1 1 1 1 1 ...
$ Neighborhood.Blmngtn : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.Blueste : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.BrDale : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.BrkSide : num 0 0 0 0 0 0 0 0 0 1 ...
$ Neighborhood.ClearCr : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.CollgCr : num 1 0 1 0 0 0 0 0 0 0 ...
$ Neighborhood.Crawfor : num 0 0 0 1 0 0 0 0 0 0 ...
$ Neighborhood.Edwards : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.Gilbert : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.IDOTRR : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.MeadowV : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.Mitchel : num 0 0 0 0 0 1 0 0 0 0 ...
$ Neighborhood.NAmes : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.NoRidge : num 0 0 0 0 1 0 0 0 0 0 ...
$ Neighborhood.NPkVill : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.NridgHt : num 0 0 0 0 0 0 0 0 0 0 ...
$ Neighborhood.NWAmes : num 0 0 0 0 0 0 0 1 0 0 ...
$ Neighborhood.OldTown : num 0 0 0 0 0 0 0 0 1 0 ...
$ Neighborhood.Sawyer : num 0 0 0 0 0 0 0 0 0 0 ...
[list output truncated]
# Count the minimum and maximum values of each column
zero_vars <- names(train)[sapply(train, function(col) all(col == 0))]
# Print all columns that are all zeros
print(zero_vars)
[1] "MSSubClass.150" "BsmtQual.Po" "BsmtCond.Ex" "KitchenQual.Po"
[5] "Functional.Sal" "PoolQC.TA" "OverallCond.10"
# If there are all zero columns, remove them
if (length(zero_vars) > 0) {
train <- train %>% select(-all_of(zero_vars))
test <- test %>% select(-all_of(zero_vars)) # Make sure test is also synchronized
}
Normalize Data (Standard Scaling)#
# Apply Standard Scaling (Z-score normalization)
scaler <- preProcess(train[, numerical_features], method = c("center", "scale"))
# Normalize train and test datasets
train[, numerical_features] <- predict(scaler, train[, numerical_features])
test[, numerical_features] <- predict(scaler, test[, numerical_features])
# Check summary to confirm scaling
summary(train[, numerical_features])
LotFrontage LotArea YearBuilt YearRemodAdd
Min. :-2.193290 Min. :-0.9234 Min. :-3.28670 Min. :-1.6888
1st Qu.:-0.454694 1st Qu.:-0.2969 1st Qu.:-0.57173 1st Qu.:-0.8654
Median :-0.008901 Median :-0.1040 Median : 0.05735 Median : 0.4424
Mean : 0.000000 Mean : 0.0000 Mean : 0.00000 Mean : 0.0000
3rd Qu.: 0.436893 3rd Qu.: 0.1087 3rd Qu.: 0.95131 3rd Qu.: 0.9268
Max. :10.823886 Max. :20.5112 Max. : 1.28240 Max. : 1.2174
MasVnrArea BsmtFinSF1 BsmtFinSF2 BsmtUnfSF
Min. :-0.5706 Min. :-0.9727 Min. :-0.2886 Min. :-1.2837
1st Qu.:-0.5706 1st Qu.:-0.9727 1st Qu.:-0.2886 1st Qu.:-0.7791
Median :-0.5706 Median :-0.1319 Median :-0.2886 Median :-0.2031
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.3383 3rd Qu.: 0.5889 3rd Qu.:-0.2886 3rd Qu.: 0.5449
Max. : 8.2824 Max. :11.4018 Max. : 8.8486 Max. : 4.0029
TotalBsmtSF 1stFlrSF 2ndFlrSF LowQualFinSF
Min. :-2.4103 Min. :-2.1434 Min. :-0.7949 Min. :-0.1202
1st Qu.:-0.5965 1st Qu.:-0.7259 1st Qu.:-0.7949 1st Qu.:-0.1202
Median :-0.1503 Median :-0.1956 Median :-0.7949 Median :-0.1202
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.5489 3rd Qu.: 0.5914 3rd Qu.: 0.8728 3rd Qu.:-0.1202
Max. :11.5170 Max. : 9.1296 Max. : 3.9356 Max. :11.6438
GrLivArea BsmtFullBath BsmtHalfBath FullBath
Min. :-2.24835 Min. :-0.8197 Min. :-0.241 Min. :-2.8408
1st Qu.:-0.73450 1st Qu.:-0.8197 1st Qu.:-0.241 1st Qu.:-1.0257
Median :-0.09794 Median :-0.8197 Median :-0.241 Median : 0.7895
Mean : 0.00000 Mean : 0.0000 Mean : 0.000 Mean : 0.0000
3rd Qu.: 0.49723 3rd Qu.: 1.1074 3rd Qu.:-0.241 3rd Qu.: 0.7895
Max. : 7.85288 Max. : 4.9617 Max. : 8.136 Max. : 2.6046
HalfBath BedroomAbvGr KitchenAbvGr TotRmsAbvGrd
Min. :-0.7614 Min. :-3.5137 Min. :-4.7499 Min. :-2.7795
1st Qu.:-0.7614 1st Qu.:-1.0621 1st Qu.:-0.2114 1st Qu.:-0.9338
Median :-0.7614 Median : 0.1637 Median :-0.2114 Median :-0.3186
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 1.2272 3rd Qu.: 0.1637 3rd Qu.:-0.2114 3rd Qu.: 0.2967
Max. : 3.2157 Max. : 6.2928 Max. : 8.8656 Max. : 4.6033
Fireplaces GarageYrBlt GarageCars GarageArea
Min. :-0.9509 Min. :-4.1189 Min. :-2.3646 Min. :-2.21220
1st Qu.:-0.9509 1st Qu.: 0.1967 1st Qu.:-1.0265 1st Qu.:-0.64769
Median : 0.6003 Median : 0.2386 Median : 0.3116 Median : 0.03283
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.00000
3rd Qu.: 0.6003 3rd Qu.: 0.2915 3rd Qu.: 0.3116 3rd Qu.: 0.48184
Max. : 3.7027 Max. : 0.3114 Max. : 2.9879 Max. : 4.42001
WoodDeckSF OpenPorchSF EnclosedPorch 3SsnPorch
Min. :-0.7519 Min. :-0.7042 Min. :-0.3592 Min. :-0.1163
1st Qu.:-0.7519 1st Qu.:-0.7042 1st Qu.:-0.3592 1st Qu.:-0.1163
Median :-0.7519 Median :-0.3269 Median :-0.3592 Median :-0.1163
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.5884 3rd Qu.: 0.3221 3rd Qu.:-0.3592 3rd Qu.:-0.1163
Max. : 6.0855 Max. : 7.5516 Max. : 8.6723 Max. :17.2113
ScreenPorch PoolArea MiscVal MoSold
Min. :-0.2701 Min. :-0.06867 Min. :-0.08766 Min. :-1.9684
1st Qu.:-0.2701 1st Qu.:-0.06867 1st Qu.:-0.08766 1st Qu.:-0.4889
Median :-0.2701 Median :-0.06867 Median :-0.08766 Median :-0.1191
Mean : 0.0000 Mean : 0.00000 Mean : 0.00000 Mean : 0.0000
3rd Qu.:-0.2701 3rd Qu.:-0.06867 3rd Qu.:-0.08766 3rd Qu.: 0.6207
Max. : 8.3386 Max. :18.29991 Max. :31.15459 Max. : 2.1002
YrSold HouseAge RemodelAge TotalSF
Min. :-1.3672 Min. :-1.20819 Min. :-1.1603 Min. :-2.7175
1st Qu.:-0.6142 1st Qu.:-0.94373 1st Qu.:-0.9181 1st Qu.:-0.6785
Median : 0.1387 Median :-0.05117 Median :-0.4336 Median :-0.1132
Mean : 0.0000 Mean : 0.00000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.8917 3rd Qu.: 0.57693 3rd Qu.: 0.8745 3rd Qu.: 0.5318
Max. : 1.6446 Max. : 3.28765 Max. : 1.7950 Max. :11.1778
Modeling#
kNN#
# Define training control
control <- trainControl(method = "cv", number = 5)
# Train KNN model (search for best k from 3 to 20)
set.seed(123)
knn_model <- train(SalePrice_log ~ .,
data = train,
method = "knn",
trControl = control,
tuneGrid = expand.grid(k = seq(2, 20, by = 2)))
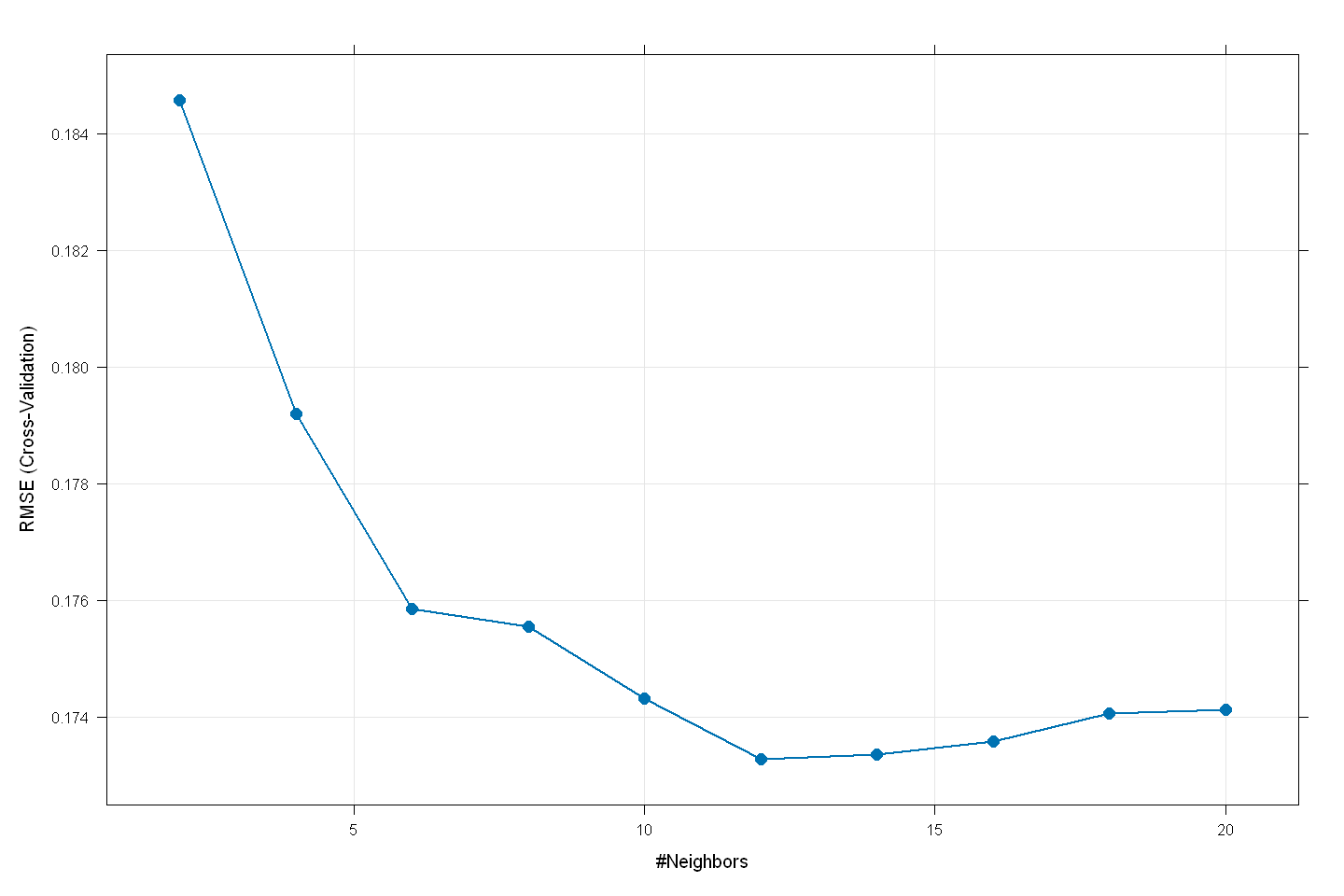
knn_model
k-Nearest Neighbors
1460 samples
336 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results across tuning parameters:
k RMSE Rsquared MAE
2 0.1845686 0.7900069 0.1276179
4 0.1792032 0.8048398 0.1211112
6 0.1758587 0.8133593 0.1193890
8 0.1755424 0.8161537 0.1199109
10 0.1743246 0.8207036 0.1192279
12 0.1732819 0.8249960 0.1188608
14 0.1733588 0.8257621 0.1195074
16 0.1735761 0.8261160 0.1197313
18 0.1740578 0.8256934 0.1201630
20 0.1741199 0.8273405 0.1204882
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was k = 12.
options(repr.plot.width = 12, repr.plot.height = 8)
plot(knn_model,
cex = 1.25,
lwd = 1.75,
pch = 16)
knn_predictions <- predict(knn_model, newdata = test)
knn_predictions <- exp(knn_predictions) # revert log-transform
knn_submission <- data.frame(
Id = Id,
SalePrice = knn_predictions
)
save_dir <- file.path("data", "house-prices", "processed(r)", "knn(r).csv")
write.csv(knn_submission, save_dir, row.names = FALSE)
SVM#
# Train SVM model with radial basis function (RBF) kernel
set.seed(123)
svm_model <- train(SalePrice_log ~ .,
data = train,
method = "svmRadial",
trControl = control,
tuneLength = 10, # Automatically searches for best parameters
scale = FALSE)
Here we set scale = FALSE because we have manually normalized numerical_features in the previous preprocessing stage. In order to avoid SVM to repeat the normalization of the extra columns generated by our one-hot encoding, we need to turn off its scale function here.
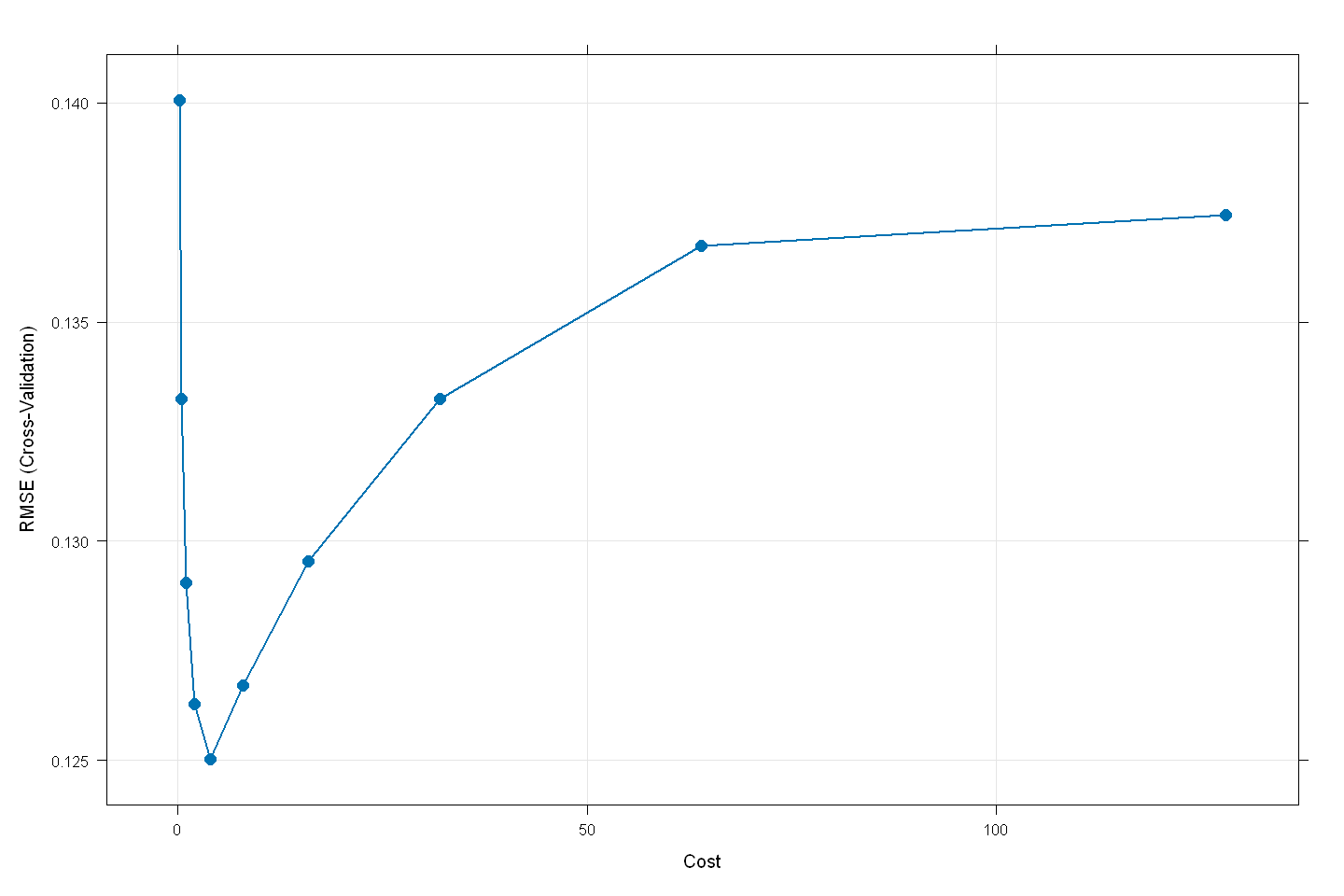
svm_model
Support Vector Machines with Radial Basis Function Kernel
1460 samples
336 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results across tuning parameters:
C RMSE Rsquared MAE
0.25 0.1400580 0.8793136 0.09348299
0.50 0.1332413 0.8900571 0.08837307
1.00 0.1290501 0.8962326 0.08551372
2.00 0.1262895 0.9005448 0.08413747
4.00 0.1250289 0.9023650 0.08437091
8.00 0.1267093 0.8999574 0.08680582
16.00 0.1295349 0.8962134 0.08979895
32.00 0.1332403 0.8906846 0.09331982
64.00 0.1367442 0.8850155 0.09608184
128.00 0.1374458 0.8838847 0.09664535
Tuning parameter 'sigma' was held constant at a value of 0.002345221
RMSE was used to select the optimal model using the smallest value.
The final values used for the model were sigma = 0.002345221 and C = 4.
plot(svm_model,
cex = 1.25,
lwd = 1.75,
pch = 16)
svm_predictions <- predict(svm_model, newdata = test)
svm_predictions <- exp(svm_predictions) # revert log-transform
svm_submission <- data.frame(
Id = Id,
SalePrice = svm_predictions
)
save_dir <- file.path("data", "house-prices", "processed(r)", "svm(r).csv")
write.csv(svm_submission, save_dir, row.names = FALSE)
Linear Regression#
# Train Linear Regression model
set.seed(123)
lr_model <- train(SalePrice_log ~ .,
data = train,
method = "lm",
trControl = control)
Warning message in predict.lm(modelFit, newdata):
"prediction from rank-deficient fit; attr(*, "non-estim") has doubtful cases"
Warning message in predict.lm(modelFit, newdata):
"prediction from rank-deficient fit; attr(*, "non-estim") has doubtful cases"
Warning message in predict.lm(modelFit, newdata):
"prediction from rank-deficient fit; attr(*, "non-estim") has doubtful cases"
Warning message in predict.lm(modelFit, newdata):
"prediction from rank-deficient fit; attr(*, "non-estim") has doubtful cases"
Warning message in predict.lm(modelFit, newdata):
"prediction from rank-deficient fit; attr(*, "non-estim") has doubtful cases"
lr_model
Linear Regression
1460 samples
336 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results:
RMSE Rsquared MAE
0.1659552 0.8347659 0.09375622
Tuning parameter 'intercept' was held constant at a value of TRUE
lr_predictions <- predict(lr_model, newdata = test)
lr_predictions <- exp(lr_predictions) # revert log-transform
lr_submission <- data.frame(
Id = Id,
SalePrice = lr_predictions
)
save_dir <- file.path("data", "house-prices", "processed(r)", "lr(r).csv")
write.csv(lr_submission, save_dir, row.names = FALSE)
Warning message in predict.lm(modelFit, newdata):
"prediction from rank-deficient fit; attr(*, "non-estim") has doubtful cases"
Lasso#
# Convert train and test to matrices for glmnet
x_train <- as.matrix(train %>% select(-SalePrice_log))
y_train <- train$SalePrice_log
x_test <- as.matrix(test)
# Train Lasso Regression (alpha = 1)
set.seed(123)
lasso_model <- cv.glmnet(x_train, y_train, alpha = 1)
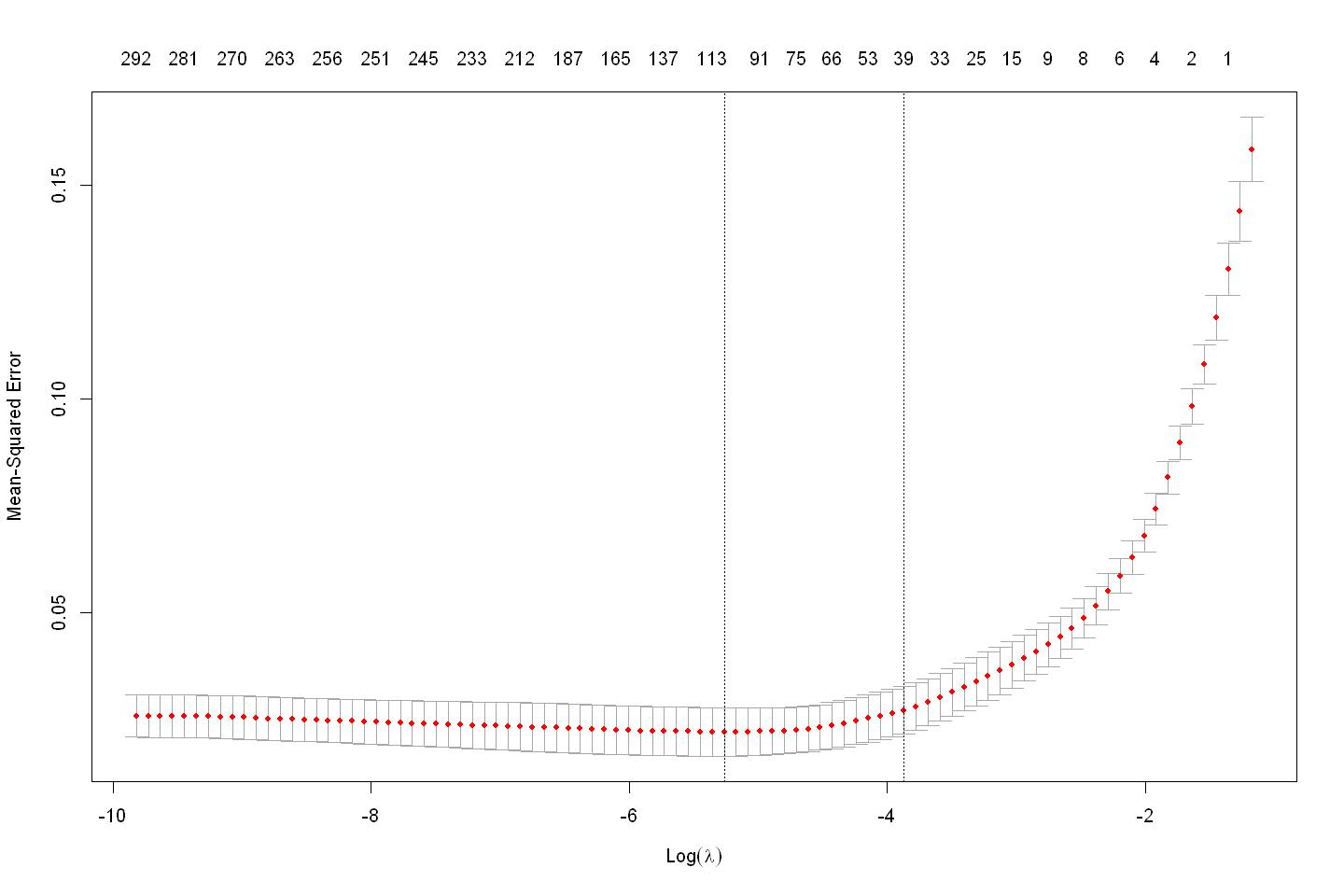
lasso_model
Call: cv.glmnet(x = x_train, y = y_train, alpha = 1)
Measure: Mean-Squared Error
Lambda Index Measure SE Nonzero
min 0.005178 45 0.02198 0.005656 105
1se 0.020902 30 0.02708 0.005587 39
plot(lasso_model)
lasso_predictions <- predict(lasso_model, newx = x_test, s = "lambda.min")
lasso_predictions <- exp(lasso_predictions) # revert log-transform
lasso_submission <- data.frame(
Id = Id,
SalePrice = as.vector(lasso_predictions) # avoid including column names
)
save_dir <- file.path("data", "house-prices", "processed(r)", "lasso(r).csv")
write.csv(lasso_submission, save_dir, row.names = FALSE)
Ridge#
# Train Ridge Regression (alpha = 0)
set.seed(123)
ridge_model <- cv.glmnet(x_train, y_train, alpha = 0)
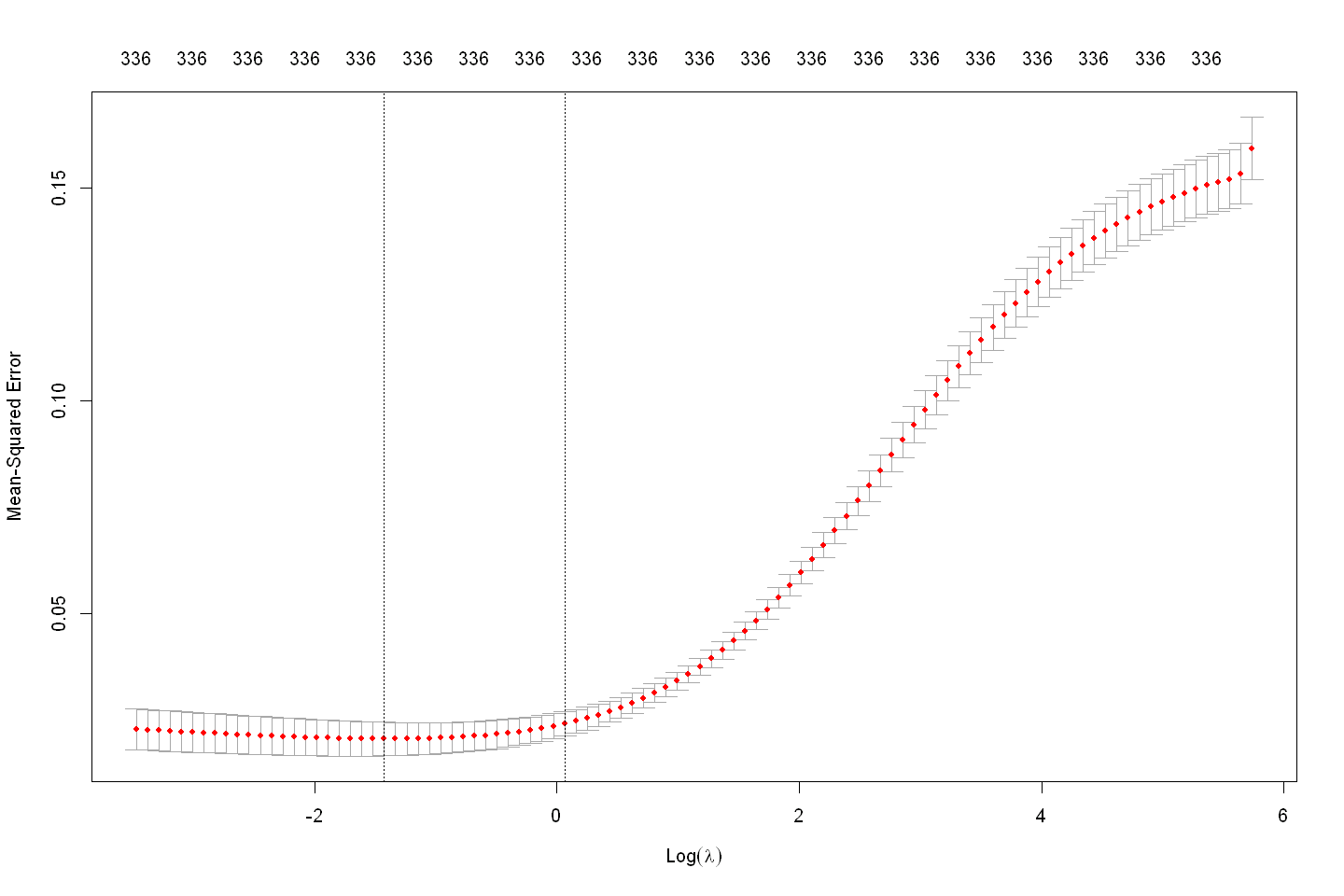
ridge_model
Call: cv.glmnet(x = x_train, y = y_train, alpha = 0)
Measure: Mean-Squared Error
Lambda Index Measure SE Nonzero
min 0.2403 78 0.02060 0.003955 336
1se 1.0648 62 0.02413 0.002847 336
plot(ridge_model)
ridge_predictions <- predict(ridge_model, newx = x_test, s = "lambda.min")
ridge_predictions <- exp(ridge_predictions) # revert log-transform
ridge_submission <- data.frame(
Id = Id,
SalePrice = as.vector(ridge_predictions) # avoid including column names
)
save_dir <- file.path("data", "house-prices", "processed(r)", "ridge(r).csv")
write.csv(ridge_submission, save_dir, row.names = FALSE)
ElasticNet#
# Train Elastic Net (alpha = 0.5)
set.seed(123)
elastic_model <- cv.glmnet(x_train, y_train, alpha = 0.5)
elastic_model
Call: cv.glmnet(x = x_train, y = y_train, alpha = 0.5)
Measure: Mean-Squared Error
Lambda Index Measure SE Nonzero
min 0.01136 44 0.02169 0.005466 108
1se 0.04180 30 0.02646 0.005162 45
plot(elastic_model)
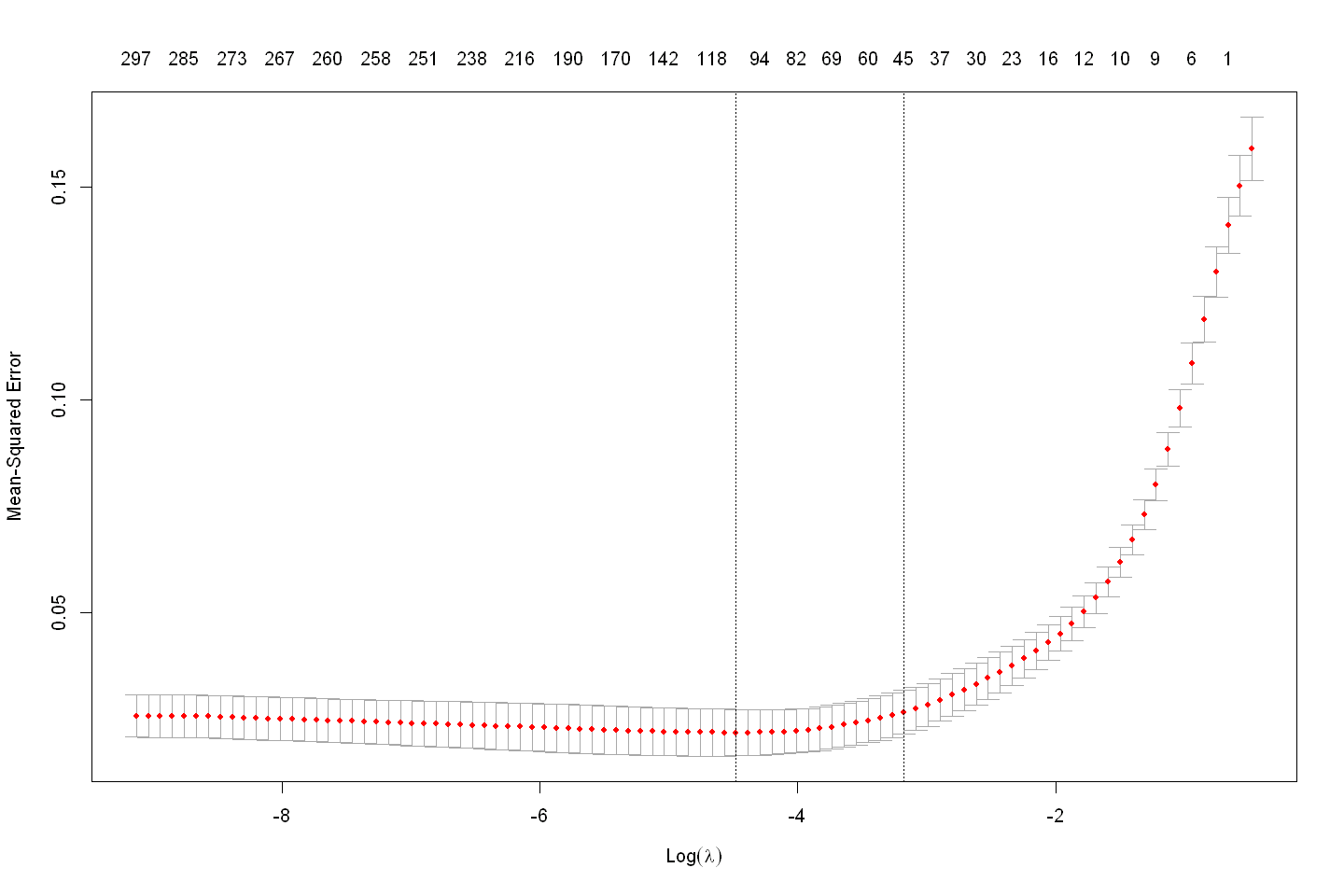
elastic_predictions <- predict(elastic_model, newx = x_test, s = "lambda.min")
elastic_predictions <- exp(elastic_predictions) # revert log-transform
elastic_submission <- data.frame(
Id = Id,
SalePrice = as.vector(elastic_predictions) # avoid including column names
)
save_dir <- file.path("data", "house-prices", "processed(r)", "elastic(r).csv")
write.csv(elastic_submission, save_dir, row.names = FALSE)
Decision Tree#
# Train Decision Tree
set.seed(123)
dt_model <- train(
x = tree_train %>% select(-SalePrice_log),
y = tree_train$SalePrice_log,
method = "rpart",
trControl = control,
tuneGrid = expand.grid(cp = seq(0.0001, 0.0005, length = 10)) # More detailed search
)
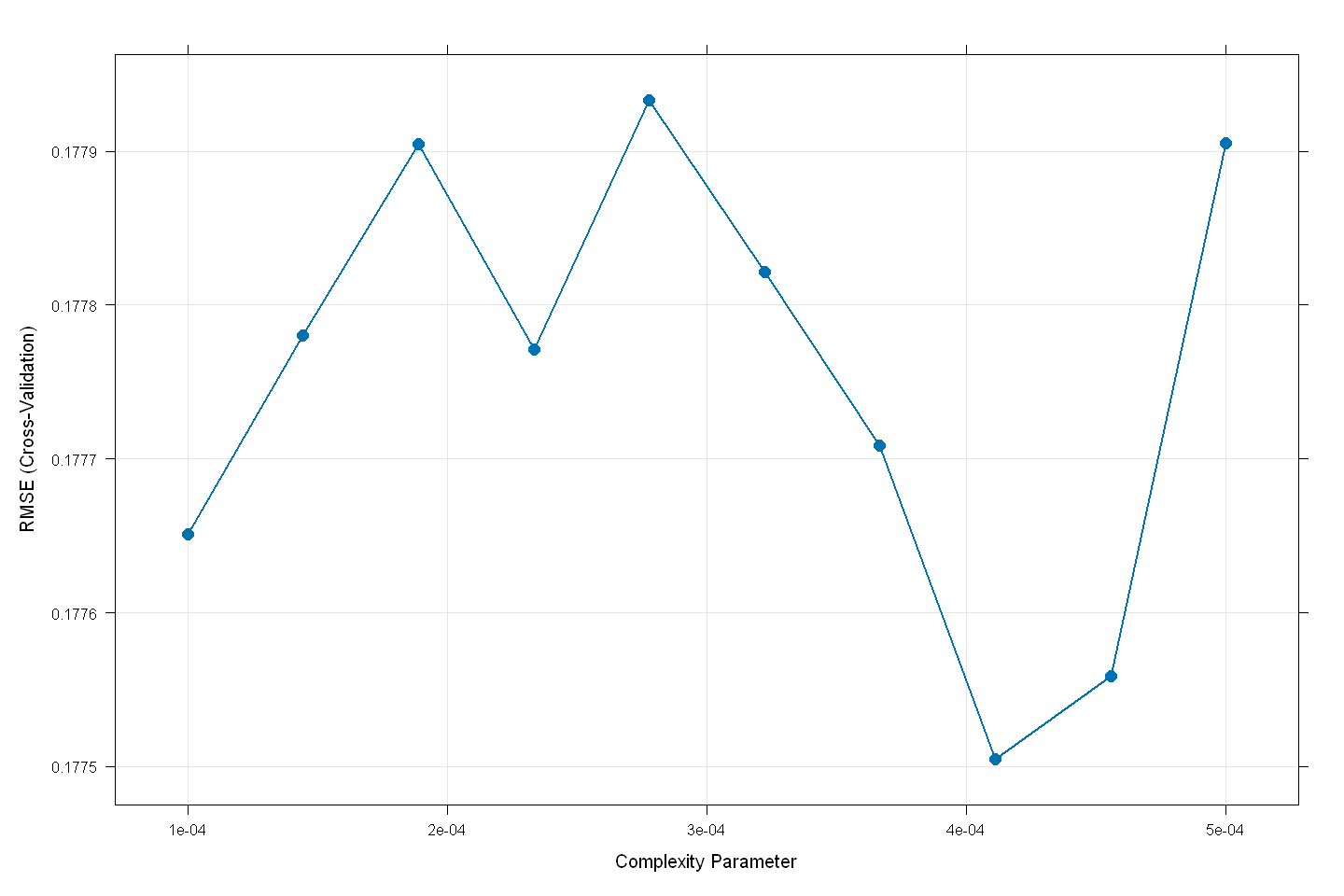
dt_model
CART
1460 samples
82 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results across tuning parameters:
cp RMSE Rsquared MAE
0.0001000000 0.1776512 0.8045802 0.1284635
0.0001444444 0.1777805 0.8042541 0.1285073
0.0001888889 0.1779049 0.8039320 0.1285442
0.0002333333 0.1777713 0.8041841 0.1279156
0.0002777778 0.1779330 0.8037993 0.1282692
0.0003222222 0.1778216 0.8038857 0.1283249
0.0003666667 0.1777085 0.8041335 0.1280759
0.0004111111 0.1775049 0.8045104 0.1281117
0.0004555556 0.1775586 0.8043727 0.1283061
0.0005000000 0.1779052 0.8034988 0.1283916
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was cp = 0.0004111111.
plot(dt_model,
cex = 1.25,
lwd = 1.75,
pch = 16)
dt_predictions <- predict(dt_model, newdata = tree_test)
dt_predictions <- exp(dt_predictions) # revert log-transform
dt_submission <- data.frame(
Id = Id,
SalePrice = dt_predictions
)
save_dir <- file.path("data", "house-prices", "processed(r)", "dt(r).csv")
write.csv(dt_submission, save_dir, row.names = FALSE)
Bagging#
# Train Bagging model (explicit feature selection)
set.seed(123)
bagging_model <- train(
x = tree_train %>% select(-SalePrice_log),
y = tree_train$SalePrice_log,
method = "treebag",
trControl = control
)
bagging_model
Bagged CART
1460 samples
82 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results:
RMSE Rsquared MAE
0.1731034 0.8162952 0.123942
bagging_predictions <- predict(bagging_model, newdata = tree_test)
bagging_predictions <- exp(bagging_predictions) # revert log-transform
bagging_submission <- data.frame(
Id = Id,
SalePrice = bagging_predictions
)
save_dir <- file.path("data", "house-prices", "processed(r)", "bagging(r).csv")
write.csv(bagging_submission, save_dir, row.names = FALSE)
Random Forest#
# Train Random Forest model
set.seed(123)
rf_model <- train(SalePrice_log ~ .,
data = tree_train,
method = "rf",
trControl = control,
tuneGrid = expand.grid(mtry = c(2, 4, 8, 16, 32, 64)),
ntree = 500) # Optimize mtry and use 500 trees
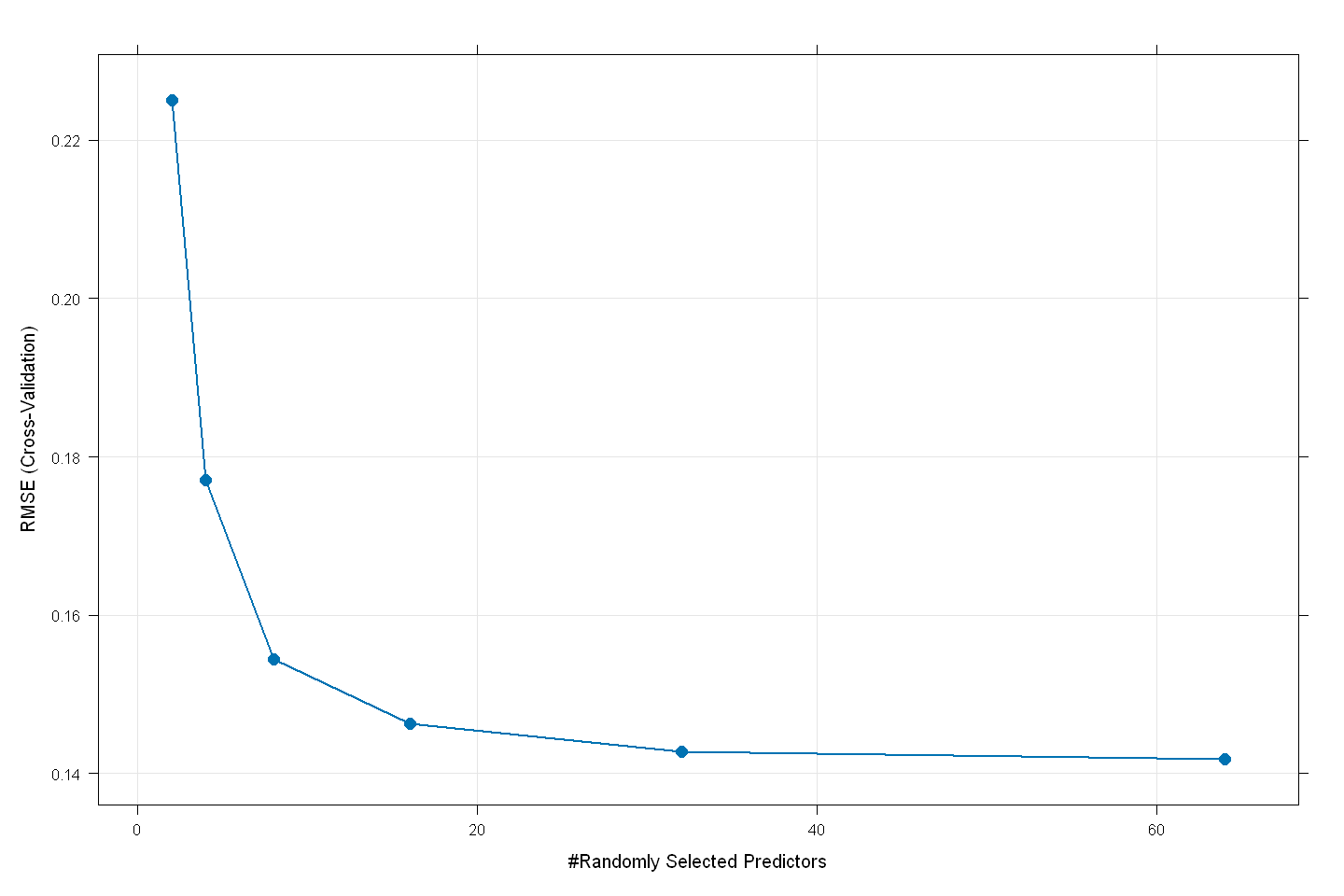
rf_model
Random Forest
1460 samples
82 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results across tuning parameters:
mtry RMSE Rsquared MAE
2 0.2249974 0.8100716 0.15743714
4 0.1770039 0.8484972 0.11895918
8 0.1544689 0.8719228 0.10174286
16 0.1462462 0.8785325 0.09590145
32 0.1427482 0.8800158 0.09394998
64 0.1418422 0.8785970 0.09393652
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was mtry = 64.
plot(rf_model,
cex = 1.25,
lwd = 1.75,
pch = 16)
rf_predictions <- predict(rf_model, newdata = tree_test)
rf_predictions <- exp(rf_predictions) # revert log-transform
rf_submission <- data.frame(
Id = Id,
SalePrice = rf_predictions
)
save_dir <- file.path("data", "house-prices", "processed(r)", "rf(r).csv")
write.csv(rf_submission, save_dir, row.names = FALSE)
XGBoost#
# Define training control for cross-validation
xgb_control <- trainControl(
method = "cv", # Cross-validation
number = 5, # 5-fold CV
verboseIter = FALSE, # Don't show training progress
allowParallel = TRUE # Enable parallel processing
)
# Define the tuning grid for hyperparameters
xgb_grid <- expand.grid(
nrounds = seq(400, 500, 600), # Number of boosting rounds
eta = c(0.01, 0.05), # Learning rate
max_depth = c(2, 3, 4), # Tree depth
gamma = c(0, 0.1), # Minimum loss reduction
colsample_bytree = c(0.8, 1), # Feature sampling ratio
min_child_weight = c(1, 2), # Minimum sum of instance weight
subsample = c(0.8, 1) # Row sampling ratio
)
# Train the XGBoost model
set.seed(123)
xgb_model <- train(
SalePrice_log ~ .,
data = tree_train,
method = "xgbTree",
trControl = xgb_control,
tuneGrid = xgb_grid,
verbosity = 0, # don't print training process
nthread = 18, # Adjust based on CPU cores
metric = "RMSE",
maximize = FALSE
)
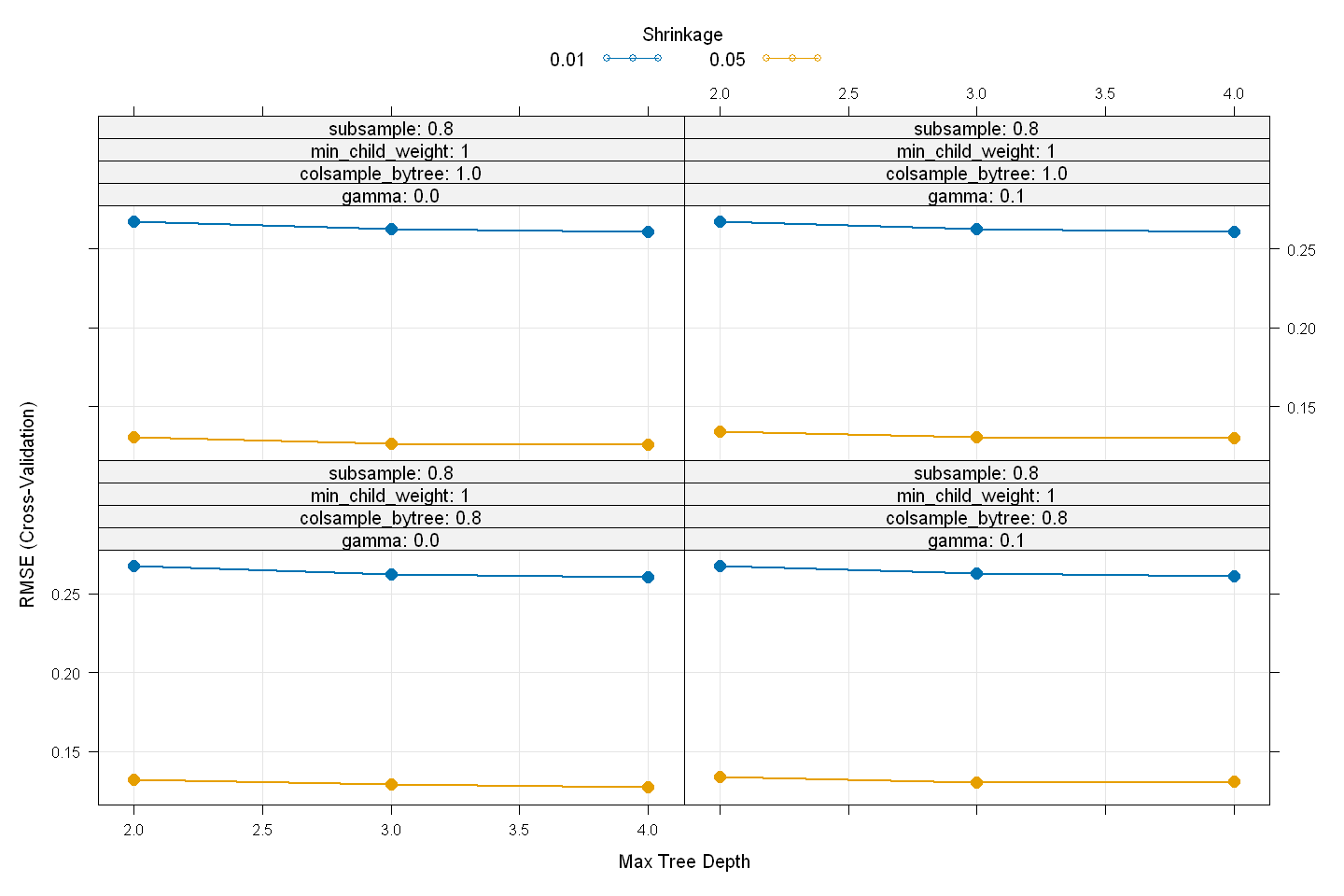
xgb_model
eXtreme Gradient Boosting
1460 samples
82 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results across tuning parameters:
eta max_depth gamma colsample_bytree min_child_weight subsample
0.01 2 0.0 0.8 1 0.8
0.01 2 0.0 0.8 1 1.0
0.01 2 0.0 0.8 2 0.8
0.01 2 0.0 0.8 2 1.0
0.01 2 0.0 1.0 1 0.8
0.01 2 0.0 1.0 1 1.0
0.01 2 0.0 1.0 2 0.8
0.01 2 0.0 1.0 2 1.0
0.01 2 0.1 0.8 1 0.8
0.01 2 0.1 0.8 1 1.0
0.01 2 0.1 0.8 2 0.8
0.01 2 0.1 0.8 2 1.0
0.01 2 0.1 1.0 1 0.8
0.01 2 0.1 1.0 1 1.0
0.01 2 0.1 1.0 2 0.8
0.01 2 0.1 1.0 2 1.0
0.01 3 0.0 0.8 1 0.8
0.01 3 0.0 0.8 1 1.0
0.01 3 0.0 0.8 2 0.8
0.01 3 0.0 0.8 2 1.0
0.01 3 0.0 1.0 1 0.8
0.01 3 0.0 1.0 1 1.0
0.01 3 0.0 1.0 2 0.8
0.01 3 0.0 1.0 2 1.0
0.01 3 0.1 0.8 1 0.8
0.01 3 0.1 0.8 1 1.0
0.01 3 0.1 0.8 2 0.8
0.01 3 0.1 0.8 2 1.0
0.01 3 0.1 1.0 1 0.8
0.01 3 0.1 1.0 1 1.0
0.01 3 0.1 1.0 2 0.8
0.01 3 0.1 1.0 2 1.0
0.01 4 0.0 0.8 1 0.8
0.01 4 0.0 0.8 1 1.0
0.01 4 0.0 0.8 2 0.8
0.01 4 0.0 0.8 2 1.0
0.01 4 0.0 1.0 1 0.8
0.01 4 0.0 1.0 1 1.0
0.01 4 0.0 1.0 2 0.8
0.01 4 0.0 1.0 2 1.0
0.01 4 0.1 0.8 1 0.8
0.01 4 0.1 0.8 1 1.0
0.01 4 0.1 0.8 2 0.8
0.01 4 0.1 0.8 2 1.0
0.01 4 0.1 1.0 1 0.8
0.01 4 0.1 1.0 1 1.0
0.01 4 0.1 1.0 2 0.8
0.01 4 0.1 1.0 2 1.0
0.05 2 0.0 0.8 1 0.8
0.05 2 0.0 0.8 1 1.0
0.05 2 0.0 0.8 2 0.8
0.05 2 0.0 0.8 2 1.0
0.05 2 0.0 1.0 1 0.8
0.05 2 0.0 1.0 1 1.0
0.05 2 0.0 1.0 2 0.8
0.05 2 0.0 1.0 2 1.0
0.05 2 0.1 0.8 1 0.8
0.05 2 0.1 0.8 1 1.0
0.05 2 0.1 0.8 2 0.8
0.05 2 0.1 0.8 2 1.0
0.05 2 0.1 1.0 1 0.8
0.05 2 0.1 1.0 1 1.0
0.05 2 0.1 1.0 2 0.8
0.05 2 0.1 1.0 2 1.0
0.05 3 0.0 0.8 1 0.8
0.05 3 0.0 0.8 1 1.0
0.05 3 0.0 0.8 2 0.8
0.05 3 0.0 0.8 2 1.0
0.05 3 0.0 1.0 1 0.8
0.05 3 0.0 1.0 1 1.0
0.05 3 0.0 1.0 2 0.8
0.05 3 0.0 1.0 2 1.0
0.05 3 0.1 0.8 1 0.8
0.05 3 0.1 0.8 1 1.0
0.05 3 0.1 0.8 2 0.8
0.05 3 0.1 0.8 2 1.0
0.05 3 0.1 1.0 1 0.8
0.05 3 0.1 1.0 1 1.0
0.05 3 0.1 1.0 2 0.8
0.05 3 0.1 1.0 2 1.0
0.05 4 0.0 0.8 1 0.8
0.05 4 0.0 0.8 1 1.0
0.05 4 0.0 0.8 2 0.8
0.05 4 0.0 0.8 2 1.0
0.05 4 0.0 1.0 1 0.8
0.05 4 0.0 1.0 1 1.0
0.05 4 0.0 1.0 2 0.8
0.05 4 0.0 1.0 2 1.0
0.05 4 0.1 0.8 1 0.8
0.05 4 0.1 0.8 1 1.0
0.05 4 0.1 0.8 2 0.8
0.05 4 0.1 0.8 2 1.0
0.05 4 0.1 1.0 1 0.8
0.05 4 0.1 1.0 1 1.0
0.05 4 0.1 1.0 2 0.8
0.05 4 0.1 1.0 2 1.0
RMSE Rsquared MAE
0.2674426 0.8427061 0.23459442
0.2665025 0.8435777 0.23389561
0.2677552 0.8420158 0.23487203
0.2666581 0.8436973 0.23402377
0.2673682 0.8421636 0.23439542
0.2663729 0.8438931 0.23386450
0.2671335 0.8429491 0.23427391
0.2663047 0.8445997 0.23384919
0.2676488 0.8418476 0.23454578
0.2666718 0.8433375 0.23398229
0.2674658 0.8420859 0.23439216
0.2663977 0.8441113 0.23384652
0.2674369 0.8420214 0.23450497
0.2664955 0.8436680 0.23393618
0.2675489 0.8423303 0.23456927
0.2663613 0.8445533 0.23385743
0.2624078 0.8580467 0.23194906
0.2617033 0.8585858 0.23177669
0.2625388 0.8570844 0.23172941
0.2616960 0.8586496 0.23162674
0.2626995 0.8572430 0.23207201
0.2618082 0.8582050 0.23182066
0.2625111 0.8582894 0.23203975
0.2617648 0.8584586 0.23161683
0.2626191 0.8569038 0.23192935
0.2618372 0.8582525 0.23179081
0.2626499 0.8561484 0.23176740
0.2615355 0.8585311 0.23126732
0.2626204 0.8570590 0.23201030
0.2618337 0.8578479 0.23178995
0.2628234 0.8565929 0.23216312
0.2617571 0.8588351 0.23159877
0.2606377 0.8655160 0.23090431
0.2600518 0.8648643 0.23082648
0.2605597 0.8664500 0.23096934
0.2599090 0.8650757 0.23045348
0.2610646 0.8647910 0.23153417
0.2601972 0.8648333 0.23080260
0.2603953 0.8652052 0.23077552
0.2600749 0.8649822 0.23053299
0.2609384 0.8631836 0.23126733
0.2599903 0.8634732 0.23069477
0.2604561 0.8650215 0.23096952
0.2602902 0.8638525 0.23064996
0.2609973 0.8640400 0.23128405
0.2599727 0.8640398 0.23053968
0.2609179 0.8642933 0.23107640
0.2600315 0.8646526 0.23052310
0.1317881 0.8918497 0.08705925
0.1328718 0.8900443 0.08964776
0.1304375 0.8940294 0.08705810
0.1314973 0.8923925 0.08895901
0.1304682 0.8939120 0.08663787
0.1322679 0.8908917 0.08996039
0.1307059 0.8934723 0.08733899
0.1312586 0.8925804 0.08949422
0.1337954 0.8885581 0.08975669
0.1359362 0.8854774 0.09270269
0.1337471 0.8887607 0.08980617
0.1361690 0.8849986 0.09251612
0.1342147 0.8879668 0.08947439
0.1363596 0.8847613 0.09287078
0.1333915 0.8891499 0.08960885
0.1359700 0.8854499 0.09268589
0.1290224 0.8959769 0.08493457
0.1266440 0.8996855 0.08537632
0.1269220 0.8991915 0.08447927
0.1285390 0.8967898 0.08641749
0.1263128 0.9003197 0.08335503
0.1274231 0.8981546 0.08600511
0.1271342 0.8986386 0.08488650
0.1282467 0.8972557 0.08592856
0.1304566 0.8940208 0.08840227
0.1335931 0.8891449 0.09106910
0.1319498 0.8916188 0.08940726
0.1345240 0.8876467 0.09157519
0.1308307 0.8931915 0.08821965
0.1353757 0.8863153 0.09263494
0.1325931 0.8904917 0.08961553
0.1350417 0.8870217 0.09242410
0.1274684 0.8982670 0.08400865
0.1265582 0.8996254 0.08542955
0.1266545 0.8995481 0.08367745
0.1274532 0.8985573 0.08495362
0.1259326 0.9006082 0.08391668
0.1270658 0.8989115 0.08554302
0.1262197 0.9002912 0.08384277
0.1276361 0.8981920 0.08526380
0.1305978 0.8936195 0.08805463
0.1324574 0.8912089 0.09047717
0.1308349 0.8935777 0.08858110
0.1340192 0.8885791 0.09124193
0.1299655 0.8948461 0.08773780
0.1355903 0.8859485 0.09312126
0.1318776 0.8916703 0.08907883
0.1351936 0.8869130 0.09290608
Tuning parameter 'nrounds' was held constant at a value of 400
RMSE was used to select the optimal model using the smallest value.
The final values used for the model were nrounds = 400, max_depth = 4, eta
= 0.05, gamma = 0, colsample_bytree = 1, min_child_weight = 1 and subsample
= 0.8.
plot(xgb_model,
cex = 1.25,
lwd = 1.75,
pch = 16)
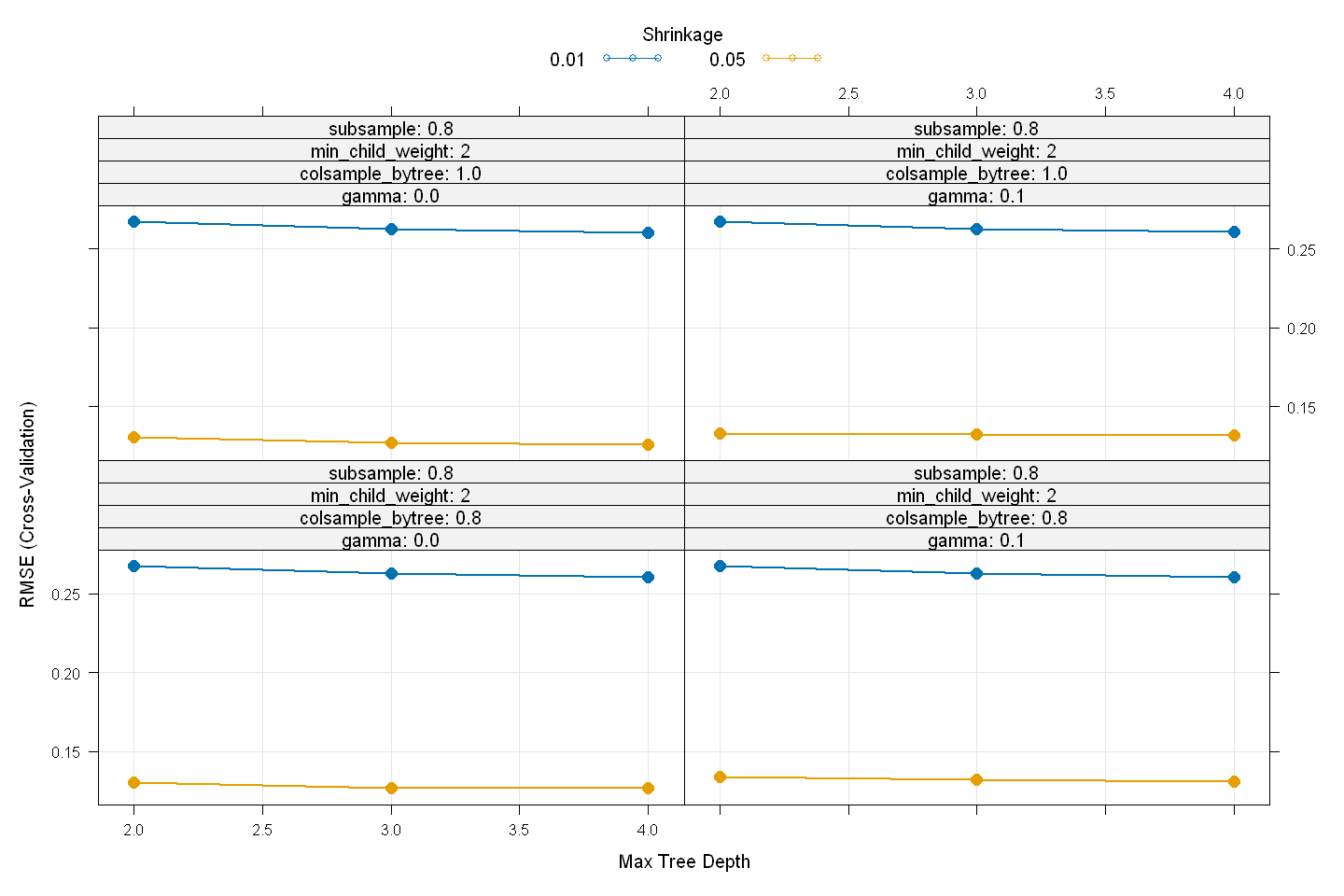
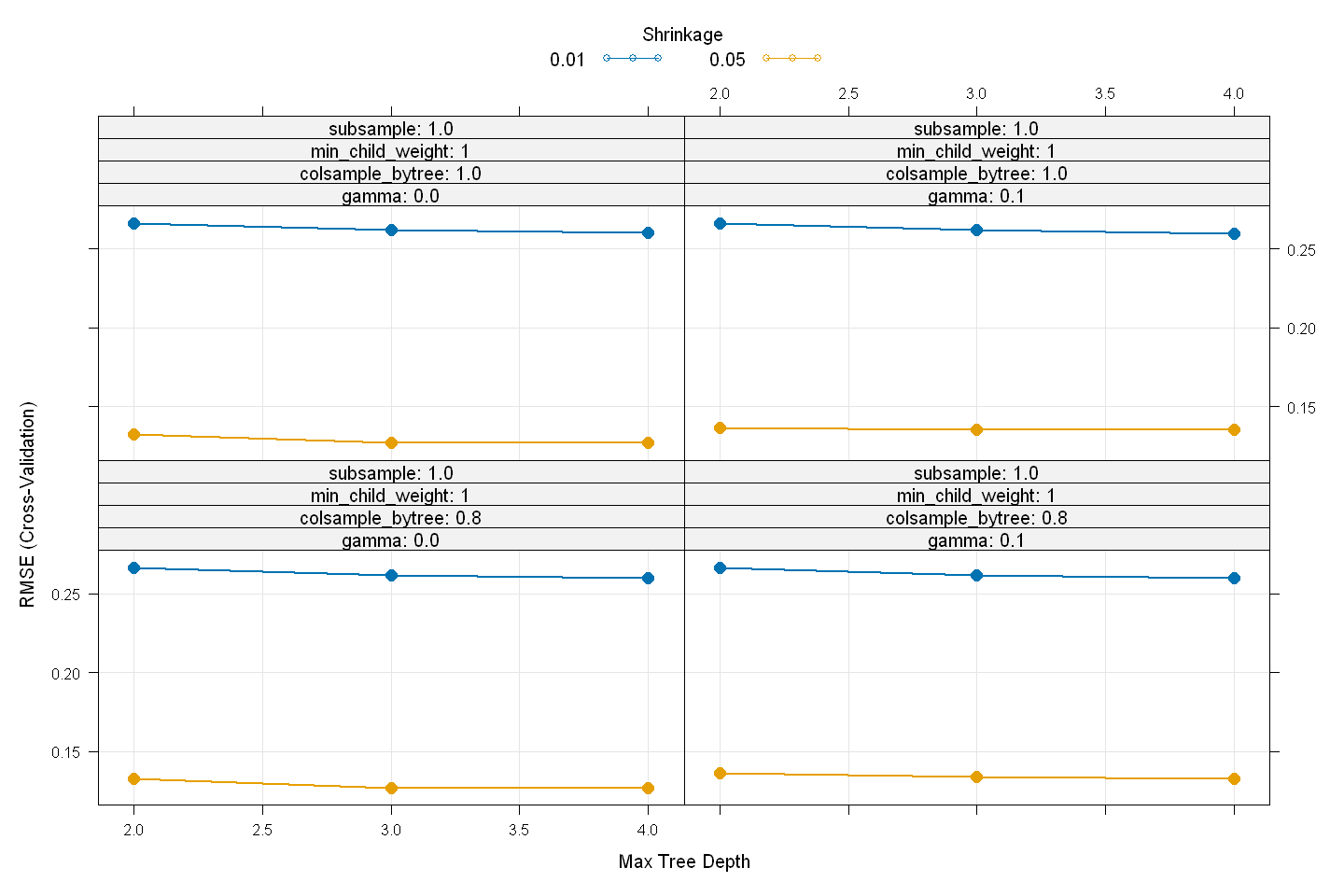
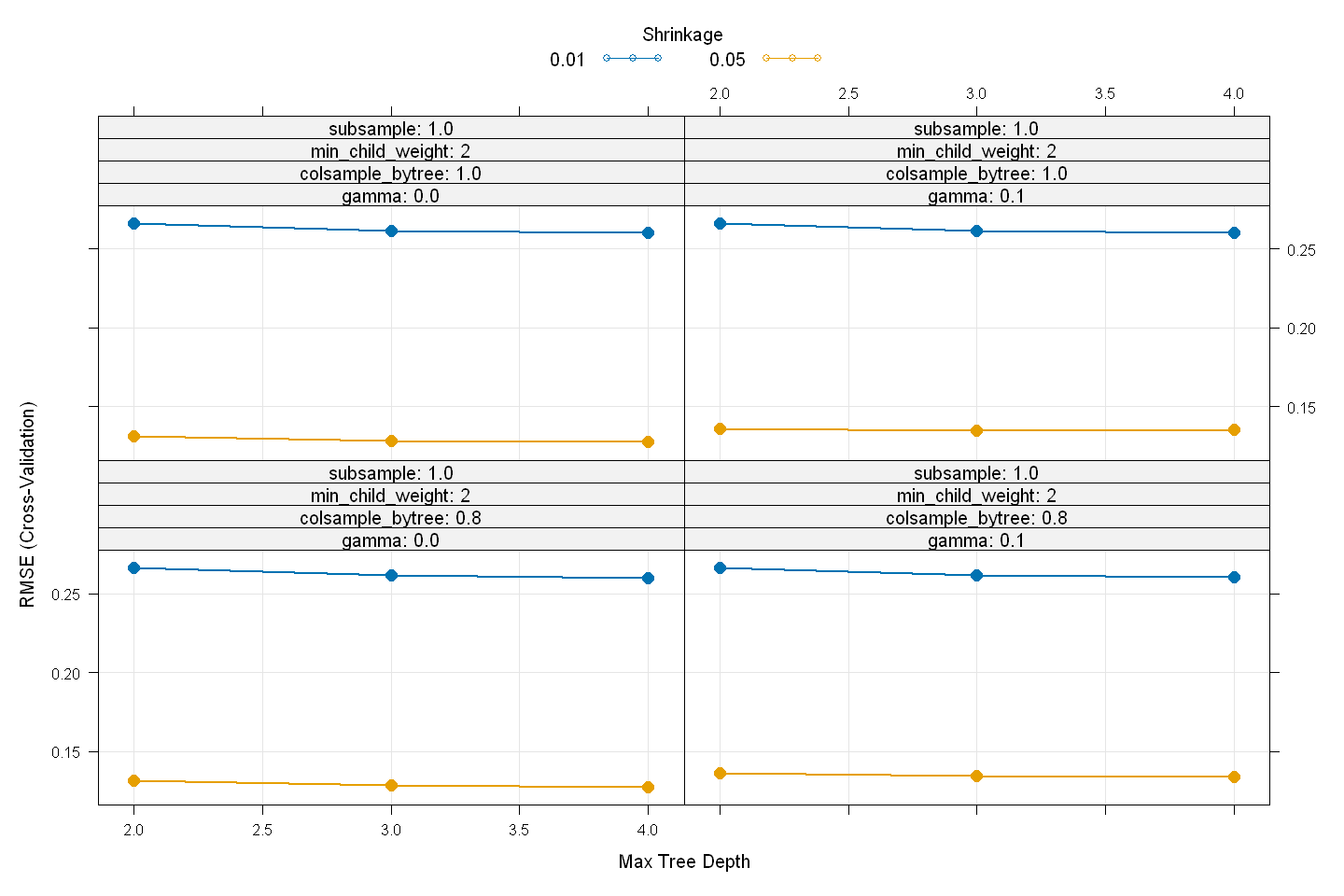
# Predict final values using model
xgb_predictions <- predict(xgb_model, newdata = tree_test)
xgb_predictions <- exp(xgb_predictions) # revert log-transform
# Prepare submission file
xgb_submission <- data.frame(
Id = Id,
SalePrice = xgb_predictions
)
# Save submission file
save_dir <- file.path("data", "house-prices", "processed(r)", "xgb(r).csv")
write.csv(xgb_submission, save_dir, row.names = FALSE)
Stacking#
# Step 1: Get predictions from base models
xgb_pred_train <- predict(xgb_model, newdata = tree_train)
xgb_pred_test <- predict(xgb_model, newdata = tree_test)
# Get the best lambda value from cross-validation
ridge_lambda <- ridge_model$lambda.min # Alternatively, use ridge_model$lambda.1se
# Predict using the trained ridge regression model
ridge_pred_train <- predict(ridge_model$glmnet.fit, newx = x_train, s = ridge_lambda)
ridge_pred_test <- predict(ridge_model$glmnet.fit, newx = x_test, s = ridge_lambda)
svm_pred_train <- predict(svm_model, newdata = train)
svm_pred_test <- predict(svm_model, newdata = test)
# Step 2: Construct Stacking Dataset
stack_train <- data.frame(
XGB = xgb_pred_train,
Ridge = ridge_pred_train,
SVM = svm_pred_train,
SalePrice_log = y_train
)
stack_test <- data.frame(
XGB = xgb_pred_test,
Ridge = ridge_pred_test,
SVM = svm_pred_test
)
# Step 3: Train Meta-Learner (Using Ridge)
set.seed(123)
stack_model <- train(
SalePrice_log ~ .,
data = stack_train,
method = "glmnet", # Using Ridge as meta-learner
trControl = trainControl(method = "cv", number = 5),
tuneGrid = expand.grid(alpha = 0, lambda = seq(0.0001, 0.1, length = 100)),
metric = "RMSE"
)
stack_model
glmnet
1460 samples
3 predictor
No pre-processing
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 1169, 1169, 1167, 1168, 1167
Resampling results across tuning parameters:
lambda RMSE Rsquared MAE
0.000100000 0.06920248 0.9712447 0.05080970
0.001109091 0.06920248 0.9712447 0.05080970
0.002118182 0.06920248 0.9712447 0.05080970
0.003127273 0.06920248 0.9712447 0.05080970
0.004136364 0.06920248 0.9712447 0.05080970
0.005145455 0.06920248 0.9712447 0.05080970
0.006154545 0.06920248 0.9712447 0.05080970
0.007163636 0.06920248 0.9712447 0.05080970
0.008172727 0.06920248 0.9712447 0.05080970
0.009181818 0.06920248 0.9712447 0.05080970
0.010190909 0.06920248 0.9712447 0.05080970
0.011200000 0.06920248 0.9712447 0.05080970
0.012209091 0.06920248 0.9712447 0.05080970
0.013218182 0.06920248 0.9712447 0.05080970
0.014227273 0.06920248 0.9712447 0.05080970
0.015236364 0.06920248 0.9712447 0.05080970
0.016245455 0.06920248 0.9712447 0.05080970
0.017254545 0.06920248 0.9712447 0.05080970
0.018263636 0.06920248 0.9712447 0.05080970
0.019272727 0.06920248 0.9712447 0.05080970
0.020281818 0.06920248 0.9712447 0.05080970
0.021290909 0.06920248 0.9712447 0.05080970
0.022300000 0.06920248 0.9712447 0.05080970
0.023309091 0.06920248 0.9712447 0.05080970
0.024318182 0.06920248 0.9712447 0.05080970
0.025327273 0.06920248 0.9712447 0.05080970
0.026336364 0.06920248 0.9712447 0.05080970
0.027345455 0.06920248 0.9712447 0.05080970
0.028354545 0.06920248 0.9712447 0.05080970
0.029363636 0.06920248 0.9712447 0.05080970
0.030372727 0.06920248 0.9712447 0.05080970
0.031381818 0.06920248 0.9712447 0.05080970
0.032390909 0.06920248 0.9712447 0.05080970
0.033400000 0.06920248 0.9712447 0.05080970
0.034409091 0.06920248 0.9712447 0.05080970
0.035418182 0.06920248 0.9712447 0.05080970
0.036427273 0.06920248 0.9712447 0.05080970
0.037436364 0.06920248 0.9712447 0.05080970
0.038445455 0.06920248 0.9712447 0.05080970
0.039454545 0.06923313 0.9712287 0.05082905
0.040463636 0.06937357 0.9711465 0.05091653
0.041472727 0.06956622 0.9710309 0.05103645
0.042481818 0.06976022 0.9709146 0.05115911
0.043490909 0.06995150 0.9708012 0.05128140
0.044500000 0.07013157 0.9706984 0.05139659
0.045509091 0.07030972 0.9705980 0.05151029
0.046518182 0.07048914 0.9704972 0.05162472
0.047527273 0.07066635 0.9703987 0.05173732
0.048536364 0.07083584 0.9703078 0.05184512
0.049545455 0.07100077 0.9702217 0.05194948
0.050554545 0.07116689 0.9701353 0.05205444
0.051563636 0.07133350 0.9700491 0.05215954
0.052572727 0.07149832 0.9699652 0.05226330
0.053581818 0.07165521 0.9698892 0.05236164
0.054590909 0.07181169 0.9698143 0.05245916
0.055600000 0.07196931 0.9697392 0.05255705
0.056609091 0.07212720 0.9696645 0.05265457
0.057618182 0.07228372 0.9695917 0.05275052
0.058627273 0.07243319 0.9695259 0.05284224
0.059636364 0.07258188 0.9694616 0.05293430
0.060645455 0.07273166 0.9693971 0.05302806
0.061654545 0.07288252 0.9693324 0.05312241
0.062663636 0.07303221 0.9692694 0.05321531
0.063672727 0.07317972 0.9692089 0.05330636
0.064681818 0.07332201 0.9691539 0.05339481
0.065690909 0.07346507 0.9690990 0.05348354
0.066700000 0.07360915 0.9690439 0.05357251
0.067709091 0.07375427 0.9689886 0.05366209
0.068718182 0.07389835 0.9689349 0.05375123
0.069727273 0.07404163 0.9688826 0.05384009
0.070736364 0.07418000 0.9688354 0.05392562
0.071745455 0.07431875 0.9687887 0.05401078
0.072754545 0.07445848 0.9687419 0.05409597
0.073763636 0.07459919 0.9686949 0.05418213
0.074772727 0.07474020 0.9686483 0.05426877
0.075781818 0.07488067 0.9686028 0.05435484
0.076790909 0.07501922 0.9685597 0.05443918
0.077800000 0.07515565 0.9685192 0.05452271
0.078809091 0.07529295 0.9684786 0.05460752
0.079818182 0.07543118 0.9684380 0.05469333
0.080827273 0.07557034 0.9683972 0.05477985
0.081836364 0.07571018 0.9683565 0.05486657
0.082845455 0.07584907 0.9683172 0.05495237
0.083854545 0.07598771 0.9682788 0.05503829
0.084863636 0.07612216 0.9682446 0.05512334
0.085872727 0.07625636 0.9682114 0.05520811
0.086881818 0.07639144 0.9681781 0.05529287
0.087890909 0.07652739 0.9681446 0.05537764
0.088900000 0.07666422 0.9681111 0.05546289
0.089909091 0.07680158 0.9680778 0.05554891
0.090918182 0.07693860 0.9680453 0.05563521
0.091927273 0.07707571 0.9680133 0.05572193
0.092936364 0.07721019 0.9679839 0.05580700
0.093945455 0.07734451 0.9679553 0.05589165
0.094954545 0.07747966 0.9679266 0.05597654
0.095963636 0.07761563 0.9678979 0.05606194
0.096972727 0.07775242 0.9678691 0.05614964
0.097981818 0.07789003 0.9678402 0.05623880
0.098990909 0.07802758 0.9678119 0.05632857
0.100000000 0.07816523 0.9677842 0.05641875
Tuning parameter 'alpha' was held constant at a value of 0
RMSE was used to select the optimal model using the smallest value.
The final values used for the model were alpha = 0 and lambda = 0.03844545.
plot(stack_model,
cex = 0.75,
lwd = 1.75,
pch = 16)
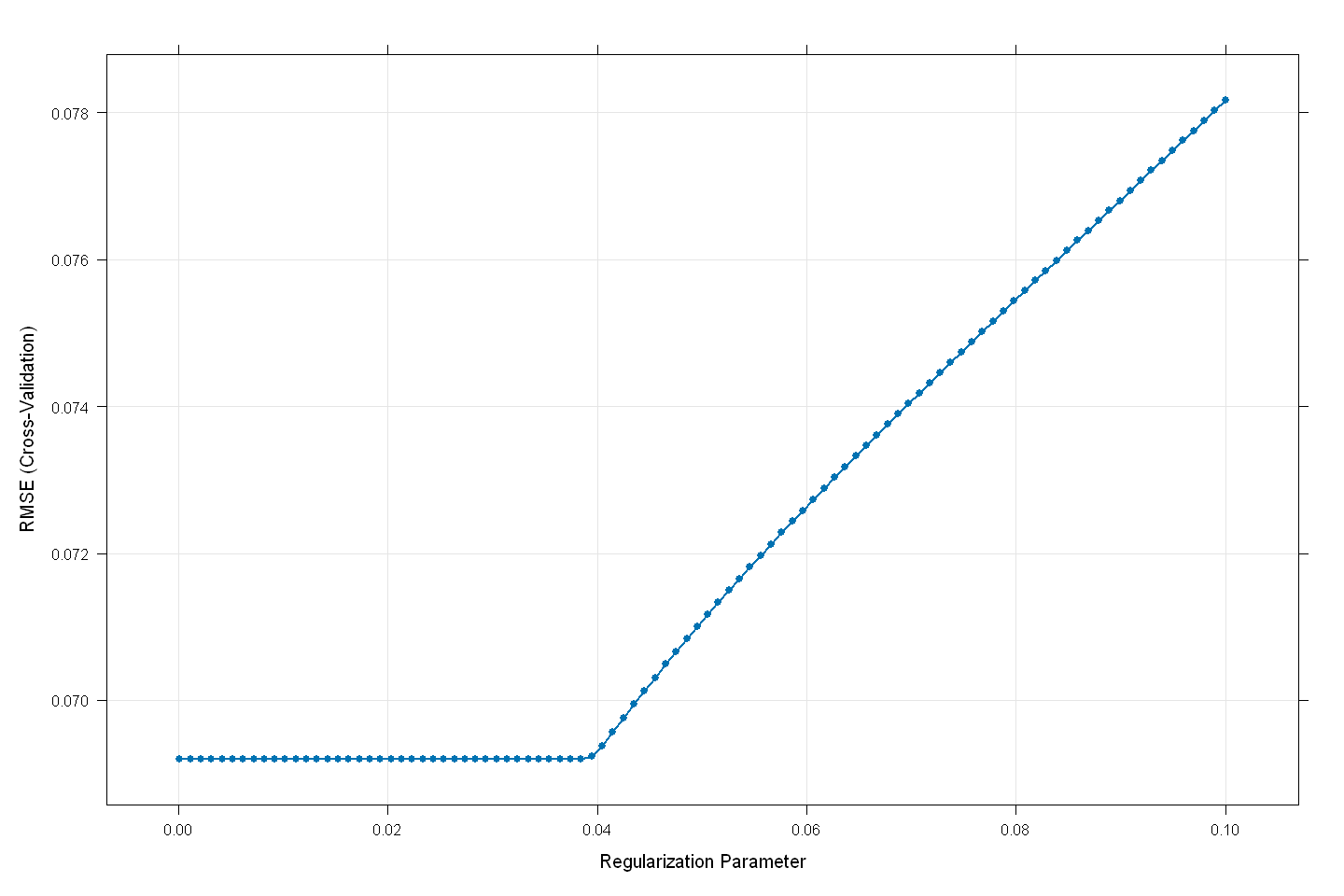
# Step 4: Make final predictions
stack_predictions <- predict(stack_model$finalModel, newx = as.matrix(stack_test), s = stack_model$bestTune$lambda)
# Step 5: Convert predictions back to original scale
stack_predictions <- exp(stack_predictions) # Assuming log-transformed target
# Prepare submission file
stack_submission <- data.frame(
Id = Id,
SalePrice = as.vector(stack_predictions) # avoid including column names
)
# Save submission file
save_dir <- file.path("data", "house-prices", "processed(r)", "stack(r).csv")
write.csv(stack_submission, save_dir, row.names = FALSE)
References#
Kaggle Competition: https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/overview
Dataset Description: https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/data